
티스토리 뷰
반응형
앞선 Bio::Blog #19에 대한 비누인형님의 글에서와 같이
"(중략) 이러한 Emergent 한 특징은 그 자체로는 우아하기 그지없지만, Engineering 이라는 목적에 있어서는 어마어마한 장애물로 나타나게 된다. 분명 각 부속품들의 동작은 이해하고 있지만, 그것들을 모아두었을 때 어떻게 움직이게 될 것인지는 알 방법이 묘연하기 때문이다.(중략) 이러한 어마어마한 장애물을 풀어헤치는데 있어서 중요한 것이 바로 simple, abstraction...(<-나름 요약)"
순전히 개인적인 생각이지만,, 이러한 것을 가능하게 하기 위한 요소중 가장 기본적인것인 바로 엄청난 컴퓨팅 파워라고 생각한다.(기본적인 것 중의 하나라고 했을뿐 꼭 필요한 요소나 뭐 가장 중요한 요소라고 안했습니다. ^^;;)
그럼 이러한 엄청난 컴퓨팅 파워는 어떻게 얻을 수 있을까? 바로 scalability가 대답이 될 수 있겠다. 하나의 문제를 해결하는데 T라는 시간이 소요된다면 N개의 문제를 처리하는데 시간은 얼마나 걸릴까?? 문제가 증가됨에 따라 컴퓨팅 자원을 증가시켜 가능한 T에 가깝게 시간을 가져가는 것이 바로 scalability의 목표가 될 수 있다. 수직적(서버의 컴퓨팅 자원을 증가시키는것,, 메모리 및 CPU의 추가) 및 수평적(서버의 수를 디따 늘리는것)확정을 모두 지원하는 선형적인 확장이 바로 컴퓨팅 파워를 얻는 방법이다.
일찍이 1967년 암달(Gene Amdahl) 박사님께서 "프로세스병렬화 한계가 반드시 존재한다는 것으로, 병렬처리가 불가능한 순차적인 부분이 있어 프로세스를 아무리 병렬화한다하더라도 더 이상 성능이 향상되지 않는 한계가 존재한다"라는 유명한 암달의 법칙을 내놓으셨다. 뭐 별로 지금의 이야기와는 상관없지만,,, 암튼,,,,
지금 꼭 꼬집어서 말씀드린다면 앞서서 말한것은 다 잊으시고,, 병렬프로그램을 만들어서 돌린다거나 하지는 않습니다. 워낙 데이터가 많다보니깐 serial한 프로그램을 여러 컴퓨터에 나뉘어져서 수행하고 있습니다. 물론 어떤 노드(컴퓨터)가 놀고 있는지,,, 그때 그때 놀고 있는 노드를 선별하고(Load Balancing), 한 노드가 작동 불능시 대처(High Availability)등을 고려해서 아무런 문제없이 여러대의 클러스터 노드들을 마치 하나의 컴퓨터처럼 사용할 수 있도록 하고 있습니다. 따라서 일반적으로 사용하는 plink, svm 등의 serial 프로그램들 되는대로 사용자들이 돌리고 싶은 것 이렇게도 돌려보고 저렇게도 돌려보고 있습니다. simple, abstraction을 위해?? ^^;; 그리고 서비스를 위해 blast가 돌고 있습니다. 병렬화된 mpiBlast도 고려해보고,, 뭐 이것저것 다양하게 쓰고 있습니다. 클러스터라고 해서 뭐 특별난건 없으니까요 ^^
저 개인적으로는 아이폰에 넣을 동영상을 인코딩하는데,,, 클러스터를 활용하는 엽기적인 행각을 실행에 옮기려고 다각도로 쳐다보는 중입니다. 이에 대한 상세한 결과는 나중에 따로 ㅎㅎ
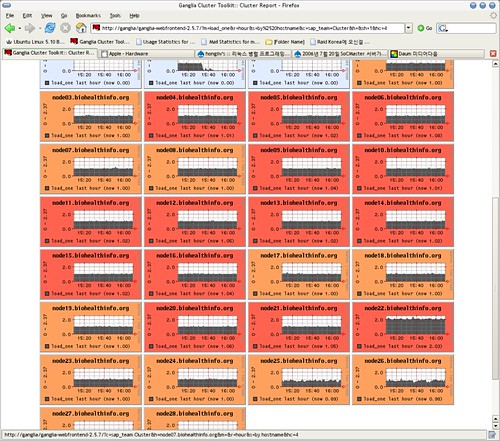
참고로 28노드 클러스터가 일하는 모습입니다. 빨개질수로 힘들게 일하고 있다는 거죠 ^^
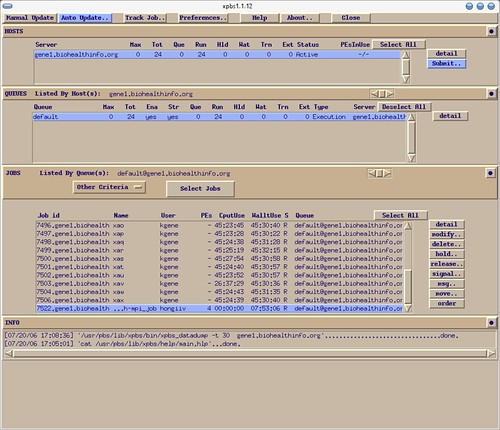
이건 제출된 일(job)의 목록을 보여주고 있습니다.
"(중략) 이러한 Emergent 한 특징은 그 자체로는 우아하기 그지없지만, Engineering 이라는 목적에 있어서는 어마어마한 장애물로 나타나게 된다. 분명 각 부속품들의 동작은 이해하고 있지만, 그것들을 모아두었을 때 어떻게 움직이게 될 것인지는 알 방법이 묘연하기 때문이다.(중략) 이러한 어마어마한 장애물을 풀어헤치는데 있어서 중요한 것이 바로 simple, abstraction...(<-나름 요약)"
순전히 개인적인 생각이지만,, 이러한 것을 가능하게 하기 위한 요소중 가장 기본적인것인 바로 엄청난 컴퓨팅 파워라고 생각한다.(기본적인 것 중의 하나라고 했을뿐 꼭 필요한 요소나 뭐 가장 중요한 요소라고 안했습니다. ^^;;)
그럼 이러한 엄청난 컴퓨팅 파워는 어떻게 얻을 수 있을까? 바로 scalability가 대답이 될 수 있겠다. 하나의 문제를 해결하는데 T라는 시간이 소요된다면 N개의 문제를 처리하는데 시간은 얼마나 걸릴까?? 문제가 증가됨에 따라 컴퓨팅 자원을 증가시켜 가능한 T에 가깝게 시간을 가져가는 것이 바로 scalability의 목표가 될 수 있다. 수직적(서버의 컴퓨팅 자원을 증가시키는것,, 메모리 및 CPU의 추가) 및 수평적(서버의 수를 디따 늘리는것)확정을 모두 지원하는 선형적인 확장이 바로 컴퓨팅 파워를 얻는 방법이다.
일찍이 1967년 암달(Gene Amdahl) 박사님께서 "프로세스병렬화 한계가 반드시 존재한다는 것으로, 병렬처리가 불가능한 순차적인 부분이 있어 프로세스를 아무리 병렬화한다하더라도 더 이상 성능이 향상되지 않는 한계가 존재한다"라는 유명한 암달의 법칙을 내놓으셨다. 뭐 별로 지금의 이야기와는 상관없지만,,, 암튼,,,,
지금 꼭 꼬집어서 말씀드린다면 앞서서 말한것은 다 잊으시고,, 병렬프로그램을 만들어서 돌린다거나 하지는 않습니다. 워낙 데이터가 많다보니깐 serial한 프로그램을 여러 컴퓨터에 나뉘어져서 수행하고 있습니다. 물론 어떤 노드(컴퓨터)가 놀고 있는지,,, 그때 그때 놀고 있는 노드를 선별하고(Load Balancing), 한 노드가 작동 불능시 대처(High Availability)등을 고려해서 아무런 문제없이 여러대의 클러스터 노드들을 마치 하나의 컴퓨터처럼 사용할 수 있도록 하고 있습니다. 따라서 일반적으로 사용하는 plink, svm 등의 serial 프로그램들 되는대로 사용자들이 돌리고 싶은 것 이렇게도 돌려보고 저렇게도 돌려보고 있습니다. simple, abstraction을 위해?? ^^;; 그리고 서비스를 위해 blast가 돌고 있습니다. 병렬화된 mpiBlast도 고려해보고,, 뭐 이것저것 다양하게 쓰고 있습니다. 클러스터라고 해서 뭐 특별난건 없으니까요 ^^
저 개인적으로는 아이폰에 넣을 동영상을 인코딩하는데,,, 클러스터를 활용하는 엽기적인 행각을 실행에 옮기려고 다각도로 쳐다보는 중입니다. 이에 대한 상세한 결과는 나중에 따로 ㅎㅎ
참고로 28노드 클러스터가 일하는 모습입니다. 빨개질수로 힘들게 일하고 있다는 거죠 ^^
이건 제출된 일(job)의 목록을 보여주고 있습니다.
반응형
공지사항
최근에 올라온 글