
티스토리 뷰
반응형
어제 저녁 11시부터 Drug Discovery and Developement 가 시작되었다. 첫째날인 어제는 Drug Discovery라는 주제라기 보다는 요즘 많이 회자되고 있는 Grid, e-Science, 협업, High Performance Computing의 주제로 일전에 분자설계연구소에서 개최한 Virtual Laboratory based on GRID Tech와 엇비슷?한 주제였다. 내가 듣고 싶었던 세션은 mpiBLAST를 만든 Wu Feng 교수의 Parallel Sequence Search with mpiBLAST였는데,, 그만 그전에 잠이 들어버렸다. 이런, 이거 들을려고 그렇게 안자고 있었건만,, ㅜㅜ
그건 그렇고 요즘 왜 이렇게 Grid기반(High Performance Computing)의 협업연구에 열광?하는 것일까?
초창기에 데이터가 생겨나니...
과학 기술과 컴퓨터의 발전으로 여러 분야에서 많은 데이터가 생겨나기 시작했다. 초창기 이러한 데이터는 당시 컴퓨팅 파워로도 충분히 처리가 가능했지만, 급속도로 발전하는 과학 기술로 인해 점점 늘어나는 데이터를 처리하기에는 점점 역부족이 되어갔다.
그리드의 탄생
그래서 생각해낸 것이 바로 분산된 컴퓨팅 자원을 모아서 사용하자는 아이디어를 실현에 옮기게 되었다. 그래서 생겨난 것이 바로 Grid 기술인 것이었다. 그런데 문제는 실질적으로 컴퓨팅 파워를 얻게 되었지만, 이를 이용해서 데이터를 분석하는 것에는 또다른 한계를 가지게 된것이다. 바로 많은 양의 데이터를 분석해도 별다른 뾰족한 답이 나오지 않는 것이다. 바로 기상청이 아무리 성능이 뛰어난 슈퍼컴퓨터를 가지고 있음에도 불구하고 날씨를 정확히 예측하지 못하고 있는 것과 같은 맥락이었던 것이다.
같이하는 연구
현시점에서 처리해야 할 그 어떤 데이터와 이것을 처리할 충분한 컴퓨팅 파워는 가지고 있지만, 이런저런 방법을 써봐도 시원한 결과가 없자, 그럼 나만 혼자 할게 아니라, 다른 분야/다른 나라의 연구기관과 아이디어를 모아서 해본다면, 뭔가 나올것 같다라는 생각을 하게 된것이다. 이게 바로 협업연구, 바로 e-Science가 된것이다.
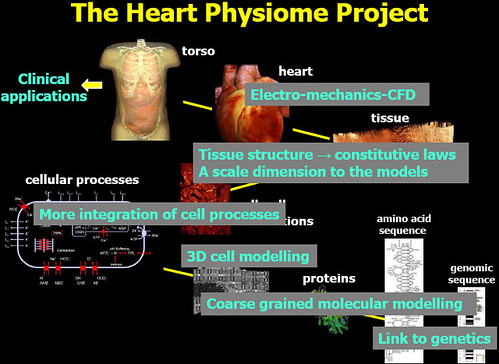
모든 분야가 어우러진,,,유체역학에서 3D cell 모델링 등등
그러나 문제는 이러한 협업을 위한 환경은 단순히 메신저를 띄우고, FTP를 통해 데이터나 주고 받는다고 해결되는 것이 아니다. 협업을 위한 각 분야의 독특한 성질?을 파악하고 그 성질에 맞는 모델을 만들어 나가고 있다. 마치 소프트웨어 분야에서의 디자인 패턴처럼,,, 각 분야에 맞는 패턴들을... 몇몇 성공한 사례들을 소개하고 있지만, 아직은 가야할 길이 더 멀어보이기는 한다.

이것으로도 부족하다
그런데, 이러한 협업하에서도 뭔가 신통치 않다면 다음 세대의 연구 환경은 어떻게 흘러갈까? 최근 대만에서는 엄청난 돈을 투자해서 유럽 입자 물리 연구소(CERN)에서 생성되는 어마어마한 데이터를 저장하는 저장소를 구축하고 있다고 한다. 혹자는 인터넷으로 다운 받으면 될것을 왜 굳이 다시 저장해 놓느냐고 한다고 한다. 누가 NCBI에서 다운 받으면 될 데이터들을 차곡차곡 자신의 하드디스크에 저장해 놓을까? 그러나,,,

전지전능한 그분의 탄생
지금은 어떻게 써야 할지 모르는 데이터 이지만, 5년, 10년 후에 세상을 깜딱 놀라게 할 AI가 나와서 처리해야 할 데이터가 모자라는 그런 상황이 온다면 사람들은 그동안 공개했던 데이터를 폐쇄하고, 아마 TV 광고에 이런 광고 문구가 "SNP 데이터 테라바이트 당 5만원 판매 - 그분에게 돌릴 수 있도록 최적화된 고도의 정제된 데이터 품질보증, 최소한 네이처 논문 5편감 ^^"
뭐 그냥 심심해서,,,,
그건 그렇고 요즘 왜 이렇게 Grid기반(High Performance Computing)의 협업연구에 열광?하는 것일까?
초창기에 데이터가 생겨나니...
과학 기술과 컴퓨터의 발전으로 여러 분야에서 많은 데이터가 생겨나기 시작했다. 초창기 이러한 데이터는 당시 컴퓨팅 파워로도 충분히 처리가 가능했지만, 급속도로 발전하는 과학 기술로 인해 점점 늘어나는 데이터를 처리하기에는 점점 역부족이 되어갔다.

그리드의 탄생
그래서 생각해낸 것이 바로 분산된 컴퓨팅 자원을 모아서 사용하자는 아이디어를 실현에 옮기게 되었다. 그래서 생겨난 것이 바로 Grid 기술인 것이었다. 그런데 문제는 실질적으로 컴퓨팅 파워를 얻게 되었지만, 이를 이용해서 데이터를 분석하는 것에는 또다른 한계를 가지게 된것이다. 바로 많은 양의 데이터를 분석해도 별다른 뾰족한 답이 나오지 않는 것이다. 바로 기상청이 아무리 성능이 뛰어난 슈퍼컴퓨터를 가지고 있음에도 불구하고 날씨를 정확히 예측하지 못하고 있는 것과 같은 맥락이었던 것이다.
같이하는 연구
현시점에서 처리해야 할 그 어떤 데이터와 이것을 처리할 충분한 컴퓨팅 파워는 가지고 있지만, 이런저런 방법을 써봐도 시원한 결과가 없자, 그럼 나만 혼자 할게 아니라, 다른 분야/다른 나라의 연구기관과 아이디어를 모아서 해본다면, 뭔가 나올것 같다라는 생각을 하게 된것이다. 이게 바로 협업연구, 바로 e-Science가 된것이다.
모든 분야가 어우러진,,,유체역학에서 3D cell 모델링 등등
그러나 문제는 이러한 협업을 위한 환경은 단순히 메신저를 띄우고, FTP를 통해 데이터나 주고 받는다고 해결되는 것이 아니다. 협업을 위한 각 분야의 독특한 성질?을 파악하고 그 성질에 맞는 모델을 만들어 나가고 있다. 마치 소프트웨어 분야에서의 디자인 패턴처럼,,, 각 분야에 맞는 패턴들을... 몇몇 성공한 사례들을 소개하고 있지만, 아직은 가야할 길이 더 멀어보이기는 한다.
이것으로도 부족하다
그런데, 이러한 협업하에서도 뭔가 신통치 않다면 다음 세대의 연구 환경은 어떻게 흘러갈까? 최근 대만에서는 엄청난 돈을 투자해서 유럽 입자 물리 연구소(CERN)에서 생성되는 어마어마한 데이터를 저장하는 저장소를 구축하고 있다고 한다. 혹자는 인터넷으로 다운 받으면 될것을 왜 굳이 다시 저장해 놓느냐고 한다고 한다. 누가 NCBI에서 다운 받으면 될 데이터들을 차곡차곡 자신의 하드디스크에 저장해 놓을까? 그러나,,,
그분??
전지전능한 그분의 탄생
지금은 어떻게 써야 할지 모르는 데이터 이지만, 5년, 10년 후에 세상을 깜딱 놀라게 할 AI가 나와서 처리해야 할 데이터가 모자라는 그런 상황이 온다면 사람들은 그동안 공개했던 데이터를 폐쇄하고, 아마 TV 광고에 이런 광고 문구가 "SNP 데이터 테라바이트 당 5만원 판매 - 그분에게 돌릴 수 있도록 최적화된 고도의 정제된 데이터 품질보증, 최소한 네이처 논문 5편감 ^^"
뭐 그냥 심심해서,,,,
반응형
공지사항
최근에 올라온 글