
티스토리 뷰
반응형
Map-Reduce나 HDFS를 지금하는 일들에 잘 써먹으면 좋을것 같다는 생각은 이전부터 가지고 있었지만, 나 혼자서 사용해서는 그 효과를 충분히 발휘 할 수 없기에 ㅋㄷㅋㄷ
우선 Hadoop을 2대의 컴퓨터에서 테스트 해봤다. 비교적 탄탄하게 잘 돌아는 간다는,,, ^^
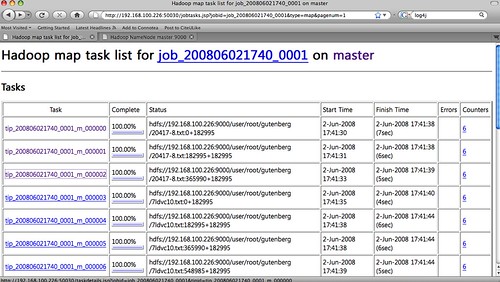
Map 수행
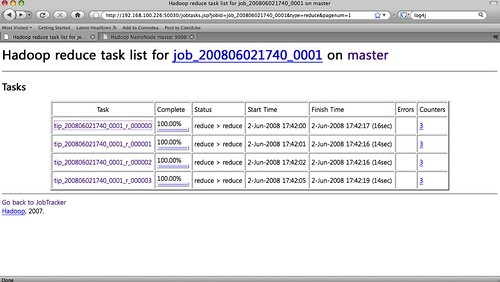
Reduce 수행
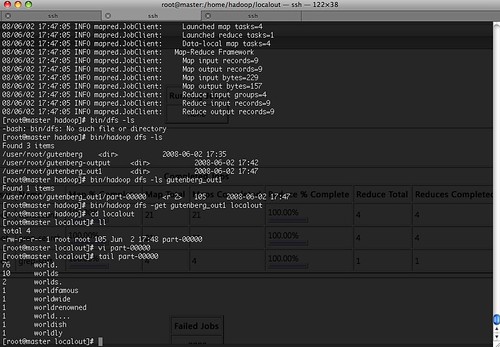
wordcount 예제,,, ^^
우선 Hadoop을 2대의 컴퓨터에서 테스트 해봤다. 비교적 탄탄하게 잘 돌아는 간다는,,, ^^
Map 수행
Reduce 수행
wordcount 예제,,, ^^
반응형
공지사항
최근에 올라온 글