
 Deep Genomics
Deep Genomics
누가 뭐래도 요즘 화두는 deep learning이 아닐까? 그렇다면 현재 genomics 또는 이와 관련하여 어떤 움직임들이 있는지 한번 알아보도록 한다. 유전질환 딥러닝 - Face2Gene 예전 칼 짐머의 "Game of Genomes"의 시즌1의 두번째 에피소드인 "깨어진 코드"편을 보면 이런 장면이 나온다. 칼 짐머가 자신의 염기서열을 시퀀싱 하기로 한후 보스턴의 브리검여성병원의 로버트 그린은 칼 짐머의 얼굴을 유심히 보는 장면이 나온다. “전 지금 유전병에서 나타나는 얼굴의 특징을 찾고 있는 거에요” 브리검여성병원(Brgham and women’s hospital)의 로버트 그린이 말했다. “눈의 모양, 귀가 너무 낮게 있지는 않은지. 귀가 복잡하게 생기진 않았는지” 그린박사는 사무실을 앞뒤로..

그리 학문적으로나 가쉽거리로나 애매한 위치의 블로그였습니다. 그냥 생각나는대로 적고 한분한분 알음알음 알아서 찾아와 주시는 분들을 보면서 제글을 읽어 주셔서 감사드리는 마음으로 그동안 블로그를 써왔었는데, 이런저런 일신상의 이유로 이제 블로그를 그만 두려고 합니다. 그동안 단맛만을 좋아해 주신 분들께 다시 한번 감사하다는 말씀드리겠습니다. 앞으로는 본 블로그의 글들은 모두 삭제될 예정이며 더이상 이주소로 접근이 불가능하게 됩니다. 혹시라도 본 블로그의 글이 필요하신분들은 백업한 XML 데이터를 보내드리도록 하겠습니다. 감사합니다.
 GenomeCloud는 이벤트 중
GenomeCloud는 이벤트 중
GenomeCloud가 기존의 서비스외에 2개의 추가적인 상품을 내놓으면서 이벤트를 하고 있습니다. 유전체 데이터를 위한 클라우드 스토리지인 g-Storage입니다. 유전체 데이터에 특화된 클라우드 스토리지인데요. 일반적인 클라우드 스토리지가 사진, 동영상, 엑셀, 워드 문서 등을 프리뷰하고 관리하게 해주는 것처럼 유전체 데이터를 프리뷰하거나 유전체 데이터의 속성을 활용하기 쉽도록 만들어져 있습니다. 예를 들어 BAM 파일의 경우 preview 하는 경우 SAM 포맷으로 보여주고요. 당근 IGV를 통해서 바로 다운로드 없이 볼 수 있습니다. 그 외에도 FastQC 결과물을 업로드하는 경우(보통 zip으로 묶여있죠)에도 프리뷰를 통해 바로 확인 가능합니다. 또한 각 파일은 샘플명이라던가 시퀀싱 타입 등의 ..
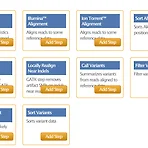 Visual Pipeline (workflow) Editor - Bioinformatics UX
Visual Pipeline (workflow) Editor - Bioinformatics UX
NGS 데이터를 비롯한 대용량의 생물학 데이터가 나타나면서 이를 분석하기 위한 위한 소프트웨어 역시 점차 그 수가 다양해지고 또한 상용화되어 가고 있다. 데이터 분석에 아마 가장 귀찮으면서도 힘든 부분이 바로 분석에 필요한 소프트웨어를 설치/설정하고 소프트웨어들의 입력과 출력을 엮어 일련의 작업을 수행하는 것이다. 이러한 일련의 소프트웨어들을 visual하게 편집할 수 있는 다양한 도구들이 나타나고 있는데 대표적인것들을 UX적으로 살펴보도록 하자. Spiral Genetics Spiral은 pipeline을 생성하는데에 있어서 각각의 소프트웨어들을 Setp이라고 부르며 이러한 step에는 Alignment, Sort, Variant Call 등의 일반적인 NGS 데이터를 위한 10개의 step들이 존재한..
 23andMe Web Site
23andMe Web Site
for prospective parents https://www.23andme.com/prospective-parents/ African Ancestry Project https://www.23andme.com/cohort/africanancestry/ Roots into the Future https://www.23andme.com/roots/ Exome https://www.23andme.com/exome/ Senior Games https://www.23andme.com/senior_games/ Parkinson's Disease https://www.23andme.com/pd/ Sarcoma Community https://www.23andme.com/sarcoma/