
티스토리 뷰
반응형
그냥 머리속에서 좋은거야~~라고만 생각했는데,, 저번 PlatformDay에서 한재선 박사님의 발표를 듣고는 Multi-Step MapReduce Programming이라는 단어와 Reusing Intermediate Data에서 실질적으로 저렇게 쓰이면 좋겠구나,,,라는 생각을 해 보았다.
뭐 사람들에게 이론적으로 아무리 말을 해도 감이 오지 않으니,, 그렇다고 WordCount와 Sort를 가지고는 너무 약하고,,, 한박사님의 발표에 쓰인 웹서버 로그를 ML로 클러스터링까지 하면야 딱 좋겠지만,,이라고 생각하던 차에 아마존에서 비슷한 웹서버 로그에 대한 예제(Running Hadoop MapReduce on Amazon EC2 and Amazon S3)를 찾았다. 나온지는 꽤 되었지만,,, 난 처음 본거라,, ^^ 몇자 적으면서 한번 테스트 해보려고 한다.
우선 전체적인 흐름은 다음과 같다.
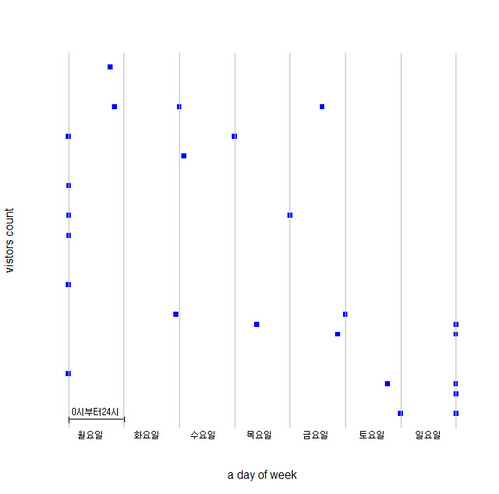
6주동안의 요일별 방문자 추이
뭐 사람들에게 이론적으로 아무리 말을 해도 감이 오지 않으니,, 그렇다고 WordCount와 Sort를 가지고는 너무 약하고,,, 한박사님의 발표에 쓰인 웹서버 로그를 ML로 클러스터링까지 하면야 딱 좋겠지만,,이라고 생각하던 차에 아마존에서 비슷한 웹서버 로그에 대한 예제(Running Hadoop MapReduce on Amazon EC2 and Amazon S3)를 찾았다. 나온지는 꽤 되었지만,,, 난 처음 본거라,, ^^ 몇자 적으면서 한번 테스트 해보려고 한다.
우선 전체적인 흐름은 다음과 같다.
- 약 100GB의 6주간의 웹서버 로그가 있다. ^^;; 어쩌지??? 저걸???
- 웹서버 로그를 분석해서 각 요일별(시간별로)로 얼만큼의 사용자가 방문했는지를 알고 싶다. 즉, 6주 동안의 월요일 전체 방문자, 화요일 전체 방문자, 수요일 전체...를 묶어서(이를 minute-in week slot이라고 부르는것 같더군 ^^) 그럼 그 결과로 대충 다음과 같은 plot이 생성되겠다.
6주동안의 요일별 방문자 추이
한박사님이 발표하신 내용보다야 간단하지만, 뭐~~~ㅋㅋㅋ 역시 주말에는 사람들이 별로군,,,(참~ 이건 그냥 제가 만들어본 plot입니다. ^^)그럼 이제 MapReduce를 이용해서 프로그래밍을 하고,,, Hadoop 클러스터를 통해서 Run한 후 결과를 R을 통해서 plot 해버리면 끝. 이건 내일,,, 밥먹으러 가야지,,,
반응형
공지사항
최근에 올라온 글