
티스토리 뷰
문헌데이터의 중요성
생물학 문헌 데이터들은 유전자, 단백질(Protein), 화학 성분(Chemical compound) 등 질병 관련 연구에 있어서 중요한 내용을 포함하고 있만 데이터의 양이 방대 하고 산재되어 있어, 연구자들이 일일이 모든 문헌 데이터 를 확인하는 것은 거의 불가능하다. 정밀종양학에 한정하여 환자의 diagnostic, prognostic, predisposing, drug response marker와 gene, variant와의 관계로 한정하여 보면,
1) BRAF V600E와 관련된 논문은 pubmed에서 2004년 5건에서 2017년 454건으로 증가
2) Oncology trial(임상시험)에서 biomarker를 이용한 시험은 전체 시험대비 2000년 ~15%에서 2018년 ~55%로 증가

Oncology 관점에서 텍스트 마이닝이 해결해야 할 실용적인 문제들
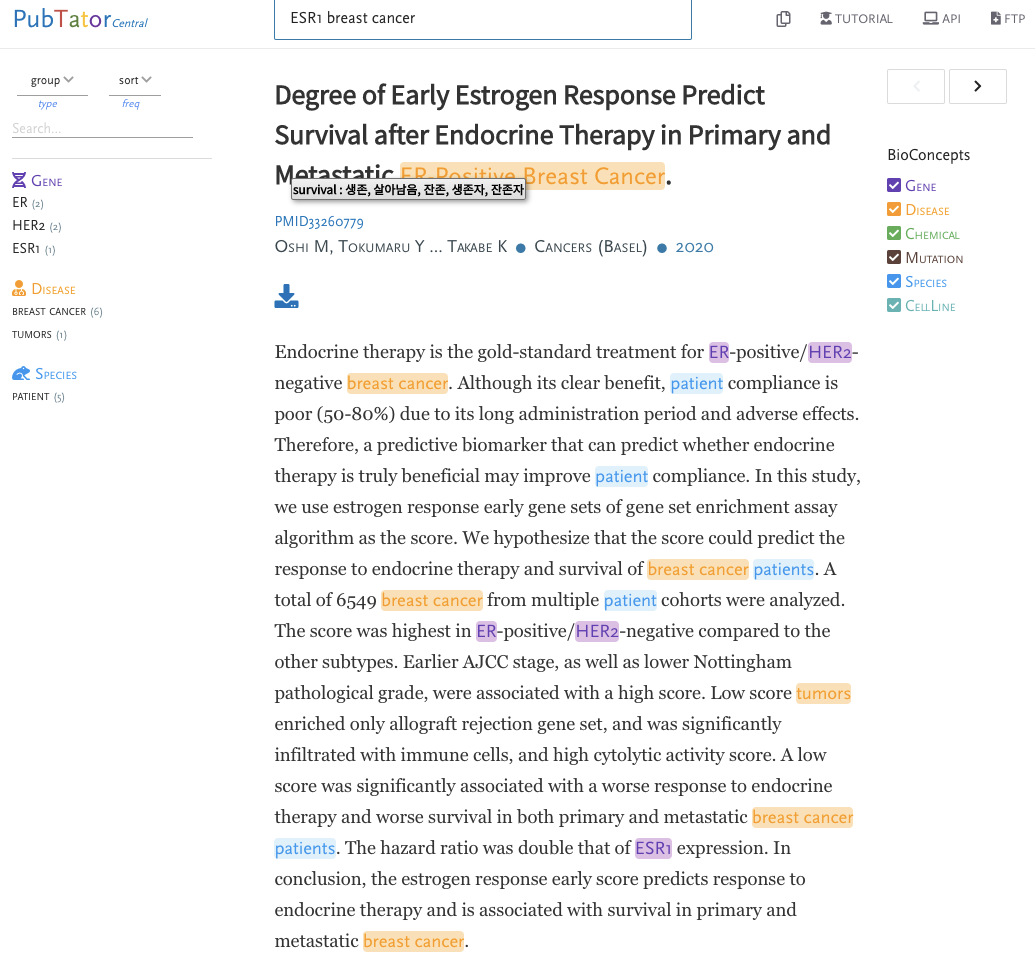
1) 환자에 대한 맞춤치료를 통한 치료의 개선을 위해서는 진단, 예측, 소인 및 약물 반응 마커에 대한 지식이 필수적으로 몇몇 knowledgebase(Cancer Genome Interpreter, CIViC, JAX-CKB, MyCancer Genome 등)들이 존재한다. 이러한 KB들은 curator에 의해 대부분 유지 관리되고 있으며, 이들이 curation하는데 있어서 텍스트 마이닝을 통해 도움을 줄 수 있다. 아래 이미지는 텍스트마이닝을 통해 문헌에서 gene, drug, disease, mutation 등의 term을 자동으로 tagging해서 보여준다.

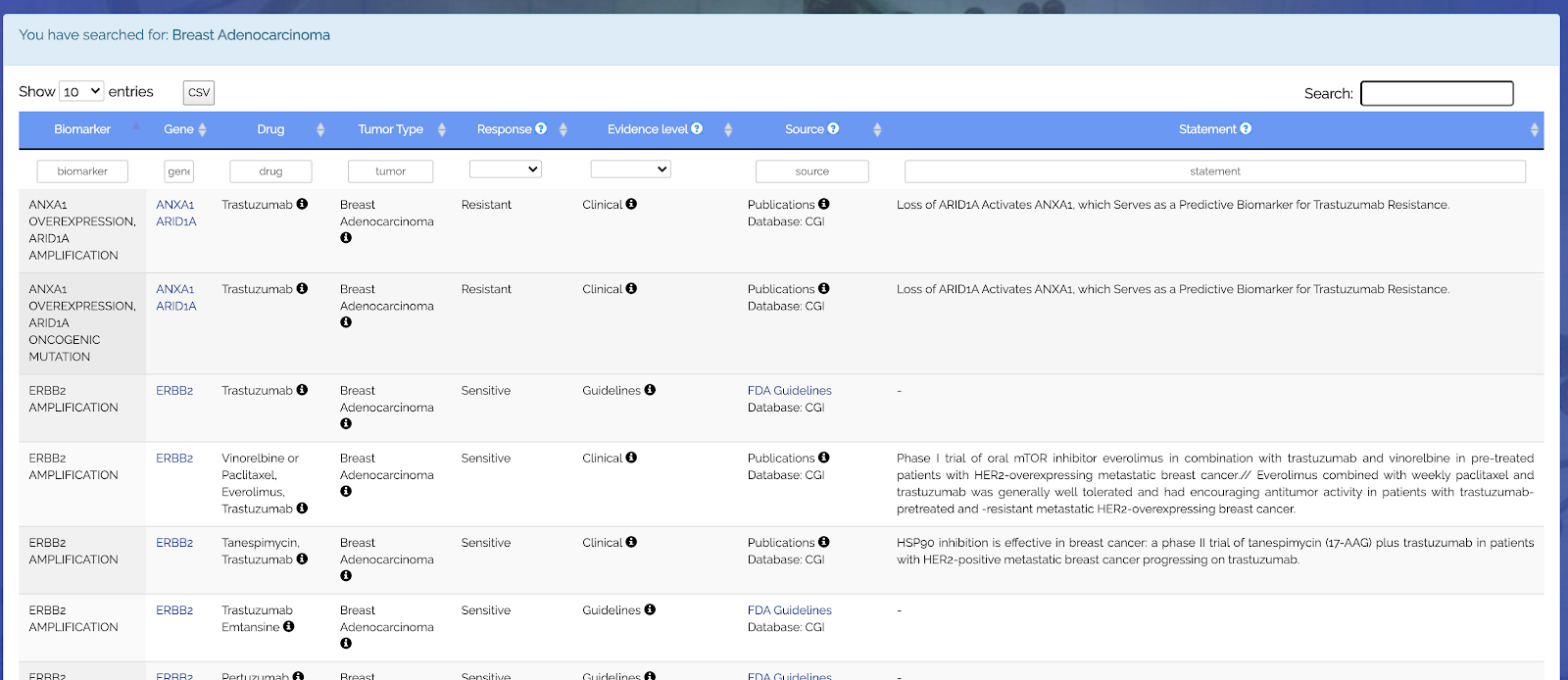
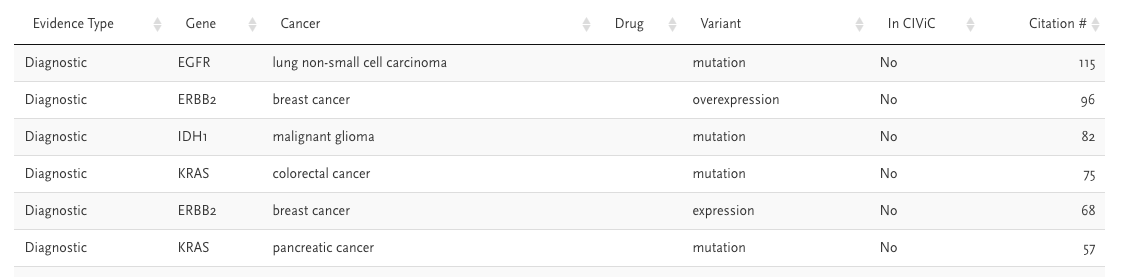
이러한 term의 entity를 추출하여 다음과 같이 정리된 형태로 제공이 가능하다.
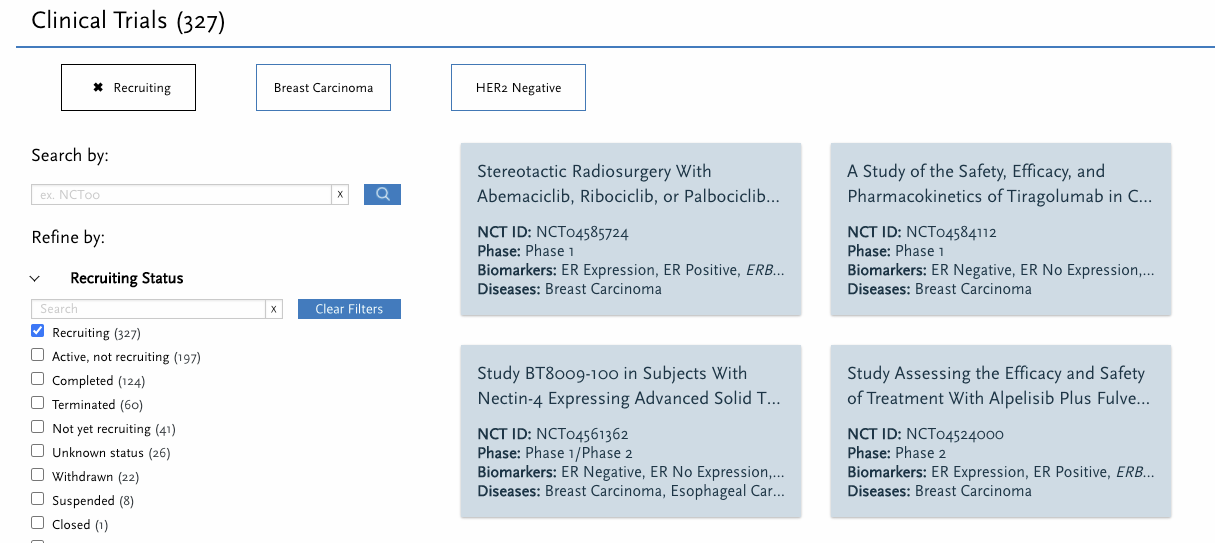
2) 이러한 문제는 앞서 설명한 임상시험의 biomarker에도 적용가능한 문제로, 바이오마커 임상시험 데이터는 구조화되어 있지 않으며, 바이오마커에 대한 설명 및 표준화가 부족하다. 이러한 바이오마커 정보는 임상시험에 대한 설명(general trial descriptions), 임상시험 포함,제외 기준(inclusion/exclusion criteria), outcome measures 또는 다른 위치에서 바이오마커의 사용을 언급할 수 있으며, 동일한 바이오마커를 설명하기 위해 다른 이름이나 두문자어를 사용할 수 있기 때문에 더 복잡해진다. 아래 그림은 현재 recruiting중인 breast cancer의 HER2 Negative 마커에 대한 임상 시험 목록을 보여준다.
텍스트 마이닝과 머신러닝을 통한 해결
텍스트 마이닝은 문헌 데이터에 나타나는 단어들을 분석하여 필요한 지식을 추출하는 방법론으로 생물학적 문헌들로부터는 다음과 같은 것들을 추출할 수 있다.
1) 유전자명, 유전변이(gene variants, CNAs, expression alterations, functional events), 단백질명 등과 같은 생물학적 개체(entity)를 추출하는 방법
2) 이러한 개체들 사이에 존재하는 관계(relationship)를 추출하는 방법
3) 개체들 사이의 관계를 네트워크(network)로 구축하는 방법
그럼 다음시간에 실제 생물학 문헌 데이터로 부터 텍스트 마이닝을 통해 entity를 추출하는 방법에 대해서 알아보도록 한다.