
티스토리 뷰
반응형
Bioinformatics Zen의 How to draw simple graphs in R이라는 글을 보면 R을 이용해서 데이터의 특성에 따라서 데이터를 그래프로 표현하는 방법에 대해서 간단하게 소개되어 있다. 여기서 간단하다는 의미는 짧고 명확하게 그리고 데이터를 어떻게 표현할지에 대해서 막막한 사람들도 고개를 끄덕이며 빠져 들 수 있다는 의미이다. 참 그리고 댓글을 읽다보면 Matlab과 Mathematica의 상용 어플리케이션과 R에 대한 논쟁(?)의 글도 있으니 댓글도 확인해 보세요 ^^;;
우선 "하루에 차(커피)를 얼마나 드십니까?" 라는 질문으로 시작하겠습니다. 이 질문에 마음속으로 대답을 하셨다면 이제 R package와 예제 데이터 파일(zip format)을 다운로드하시고 차한잔을 옆에 두고 천천히 읽어나가시기 바랍니다. ^^
여기서는 다음의 4가지 유형의 데이터를 그래프로 어떻게 표현하는지에 대해서 설명합니다.
1. Categorical data
2. Continuous data
3. Factored categorical data
4. Factored cotinuous data
Categorical data
첫번째로 Categorical data는 이름을 가지고 있으며, 숫자형이 아닌 값을 가지고 있는 경우입니다. 원형, 사각형, 삼각형같은 경우가 되겠죠. 또는 대, 중, 소와 같은 것도 카테고리 데이터에 속하겠습니다. 여기서는 system biology, Functional genomicsm Non-coding RNA의 각각 3가지 연구영역의 연구자들이 하루에 마시는 차의 횟수 데이터를 가지고 진행합니다.
categorical data 파일 categorical.csv를 읽어들인다.
> data <- read.csv("path/to/file/categorical.csv")
ls()를 통해서 data object가 읽어들여진것을 확인한다.
> ls()
[1] "data"
data object는 앞서 말한것과 같이 3개의 바이오인포매틱스 연구영역(이것이 category가 되겠죠)과 이영역의 연구자들이 하루에 얼마나 많은 양의 차를 마시는지에 대한 데이터가 있다.
> head(data)
Systems.biology Functional.genomics Non.coding.RNA
1 2 4 5
2 2 4 7
3 2 1 7
4 2 4 5
5 2 3 5
6 2 3 4
1,2,3....6이라고 씌어진 첫번째 컬럼은 행번호(row number)이며, 뒤이은 3개의 컬럼이 하루에 마시는 차의 양을 나타낸다. 언뜻 보더라도 Non-coding RNA 연구자들이 꽤 많이 마시는듯..??
자 그럼 categorical 데이터를 어떻게 가시화 시킬것인가? 첫번째로 해야할 일은 데이터를 다른 포맷으로 변경하는 일이다. 첫번째 컬럼에 System biology가 있고 그 이후로 다른 영역의 데이터가 존재하는 형태이다. 이러한 형태를 지금부터 "wide"라고 하겠다. 만약 100개의 연구영역이 존재한다면 100개의 컬럼으로 구성된 넓은 형태로 보여지기 때문이다. 따라서 "long" 포맷의 길다란 모양으로 데이터를 변형시키도록 하겠다.
wide를 long 형태로 변형하기 위해서는 R package의 reshape 패키지를 사용한다. reshape는 R에 기본적으로 포함되지 않기 때문에 요기를 참고해서 패키지를 설치한다. 이제 설치한 패키지를 로드한다.
> library(reshape)
그런다음 다음의 명령어로 reshape를 수행한다.
> data <- melt(data,measure.var=c("Systems.biology","Functional.genomics","Non.coding.RNA"))
그러면, 다음과 같이 3개의 변수로 구분된 데이터를 long 형태로 확인할 수 있다.
> head(data)
variable value
1 Systems.biology 2
2 Systems.biology 2
3 Systems.biology 2
4 Systems.biology 2
5 Systems.biology 2
6 Systems.biology 2
첫번째 컬럼은 bioinformatics 타입, 두번째 컬럼은 하루에 먹는 차의 양 형태로 보여준다. 이제 phylogenetics와 같은 다른 연구 영역을 추가하더라도 열만 추가 된다.
이제 어떤 영역의 연구자들이 가장 많이 차를 마시는지 plot을 이용하여 데이터를 보여주도록 하자. 여기서는 lattice라는 R 패키지를 이용할 것이다. lattice 패키지는 기본적으로 R에 포함되어 있기 때문에 별도의 패키지 설치 과정없이 다음과 같이 호출하면 된다.
> library(lattice)
categorical 데이터를 표현하기 위한 가장 좋은 plot은 box and whisker plot이다. lattice의 bwplot(box and whisker plot)을 이용하여 plot을 생성하자.
> plot <- bwplot(value ~ variable, data = data)
> plot$ylab <- "Cups of Tea per day"
> print(plot)
bwplot의 value ~ variable은 R에서의 값,value(즉 하루에 먹은 차의 양)와 변수,variable(바이오인포매틱스 연구분야)를 위미한다. 그 다음의 data=data의 의미는 R에서의 plot을 그리기 위한 데이터가 R 객체 data에 저장되어있다는 것을 의미한다. 그 결과를 plot이라는 R 객체에 넣어둔다. 그 다음 줄인 plot$ylab은 y축의 라벨을 cups of tea per day로 지정하는 것이다. 마지막으로는 print(plot)을 이용해서 plot 객체를 그래픽 디바이스로 출력하라는 의미이다.
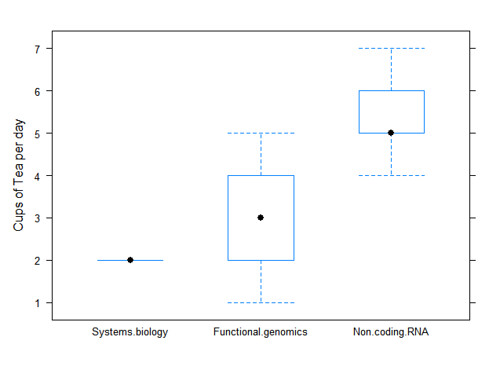
이제 이 그래프 하나로 하루에 몇잔의 차를 마시는지 알기 쉽게 볼 수 있게 되었다. system biologists는 정확하게 하루에 2잔씩, functional genomists는 1~5잔을, non-coding RNA-ist는 최대 7잔까지 ^^
Continuous data
앞서서 각 연구 분야별(categorical data) 하루 마시는 차의 양에 대해서 그래프를 그려봤는데, 이번에는 Continuous data에 대해서 알아보도록 하겠습니다. continuous 데이터는 숫자 형식의 데이터이다. 앞서서와 마찬가지로 파일을 읽어 들인다.
> data <- read.csv("path/to/file/continuous.csv")
> head(data)
distance productivity
1 54.86337 35.05450
2 53.97946 35.66953
3 53.74379 35.00325
4 41.41431 35.23826
5 73.96309 32.07927
6 58.19178 33.35028
이 데이터는 바이오인포매틱스 연구자와 차를 만드는 방까지의 거리와 한 주동안의 생산성을 나타내고 있다. 이 데이터는 이전에 말한 두개의 컬럼으로 이루어져 long 형태의 데이터포맷으로 잘 이루어져 있다.
이러한 두개의 continuous 변수를 가장 잘 비교하기 위한 위한 벙법은 xyplot으로 각각을 축으로 나타내면 된다. 생산성에 대한 "차를 만드는 방까지의 거리"에 대하여 이전과 마찬가지 방법으로 plot을 생성한다. 이때 xyplot 함수와 각각의 x, y축에 대한 라벨을 생성한다.
> plot <- xyplot(productivity ~ distance, data=data)
> plot$xlab <- "Distance to tea making area (feet)"
> plot$ylab <- "Weekly productivity (hours)"
> print(plot)
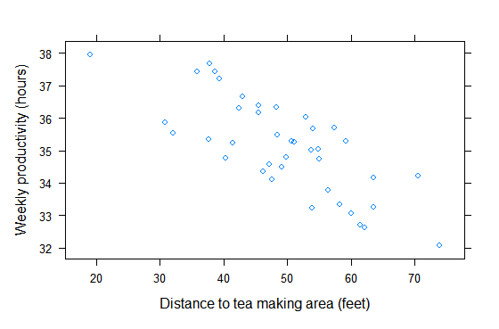
위의 결과를 통해 차를 만드는 장소가 가까울수록 생산성이 좋아진다는 것을 알 수 있다. 이렇게 만들어진 plot에 (x,y)축 안쪽에 선을 하나 추가하기 위해 "panel"을 한 생성한다. panle.xyplot을 사용하여 사용자 정의 panel을 추가한다.
> custom_panel_lm <- function(x,y) {
panel.xyplot(x,y)
panle.lmline(x,y)
}
> plot$panel <- custom_panel_lm
> print(plot)
첫번째 function(x,y) x와 y(x,y는 continuous 변수)를 인자로 같는 함수를 정의하고 있다. 이 함수는 두개의 메소드를 호출하고 있는데, 첫번째는 panel.xyplot 함수로 plot을 그리는 함수, 두번째는 x,y 인자를 가지고 선형 추세선을 그린다. 이렇게 만들어진 함수를 이전 plot에 panel을 추가하고 print하면 된다.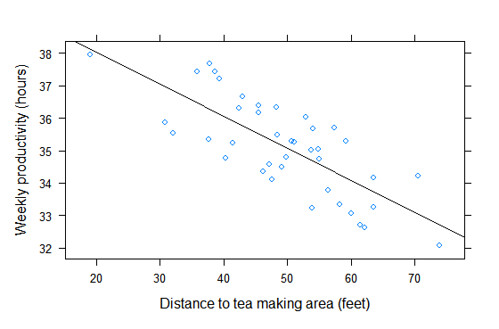
이제 선을 통해서 거리와 생산성과의 관계를 좀더 확실하게 보여준다. 그럼 데이터의 좀더 정확한(?) 동향을 위해서 좀 울퉁불퉁한 선을 추가하도록 하자.
> custom_panel_loess <- function(x,y) {
panel.xyplot(x,y)
panle.loess(x,y)
}
> plot$panel <- custom_panel_loess
> print(plot)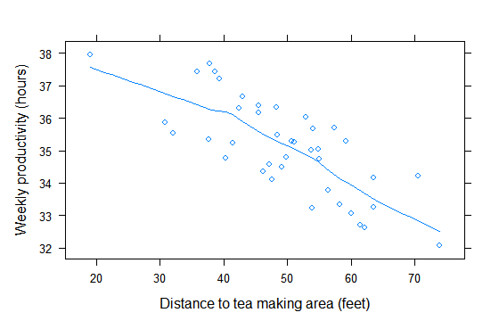
Factored categorical data
지금까지 연구자들이 얼마나 많은 양의 차를 마시는지에 대한 추세(??추이, 경향)를 봤다. 그러나 계절에 따라서 이러한 추세를 보고자 한다면, 여름에 비해서 겨울은 어떠한지 말이다. 이것에 대한 데이터가 categorical_categorical.cvs에 있다.
> data <- read.csv("path/to/file/categorical_categorical.csv")
> head(data)
SB FG ncRNA SB.1 FG.1 ncRNA.1
1 2 2 4 0 1 7
2 2 2 5 0 2 6
3 2 4 6 0 5 8
4 2 4 4 0 3 7
5 2 2 5 0 1 6
6 2 1 4 0 2 8
자 wide형태이 데이터 형태를 가지고 있으며, 첫번째 3개의 컬럼은 겨울철 데이터를 나머지 3개의 컬럼은 여름철의 데이터를 나타내고 있다. 첫번째 categorical 데이터는 연구분야(area of research), 두번째 category는 계절(season)이 된다.
> winter <- data[,1:3]
> summer <- data[,4:6]
> winter <- melt(winter,measure.var=c(”SB”,”FG”,”ncRNA”))
> summer <- melt(summer,measure.var=c(”SB.1″,”FG.1″,”ncRNA.1″))
첫번째로는 long 형태로 바꾸는 작업을 수행해야 한다. 여기서 3개의 컬럼이 필요하다. 하루동안 마시는 차의 양, 연구분야, 계절의 3개의 변수를 사용할것이기 때문이다.
> head(winter)
variable value
1 SB 2
2 SB 2
3 SB 2
4 SB 2
5 SB 2
6 SB 2
> head(summer)
variable value
1 SB.1 0
2 SB.1 0
3 SB.1 0
4 SB.1 0
5 SB.1 0
6 SB.1 0
이제 별도의 계절 변수를 추가하기로 한다. 이 변수는 새로운 컬럼으로 등록된다.
> summer <- cbind(summer,season="summer")
> winter <- cbind(winter,season="winter")
cbind는 새로운 컬럼을 추가하는 명령으로, season이라는 컬럼을 만들고 여기에 summer와 winter 값을 각각 넣었다. 다시 winter와 summber 객체를 보면 다음과 같다.
> head(summer)
variable value season
1 SB.1 0 summer
2 SB.1 0 summer
3 SB.1 0 summer
4 SB.1 0 summer
5 SB.1 0 summer
6 SB.1 0 summer
> head(winter)
variable value season
1 SB 2 winter
2 SB 2 winter
3 SB 2 winter
4 SB 2 winter
5 SB 2 winter
6 SB 2 winter
이제 새로운 season 컬럼이 생긴것을 확인할 수 있다. 마지막으로 두개의 데이터 세트를 함께 합쳐야 한다.
> data <- rbind(winter,summer)
rbind 는 새로운 행으로 묶으라는 명령이다. 이제 summer 데이터 아래에 winter 데이터가 합쳐졌다. 이제 한가지만 하면 plot을 생성할 수 있다. 여기서 summer 데이터에는 각 연구분야.1 형태로 .1이 붙어 있다. leveles로 변수 컬럼을 살펴보면 다음과 같이 .1이 붙어 있다.
> levels(data$variable)
[1] "SB" "FG" "ncRNA" "SB.1" "FG.1" "ncRNA.1"
이제 .1을 제거하고 처음 나오는 3개의 변수를 대체해보도록 하자.
> levels(data$variable)[4:6] <- levels(data$variable)[1:3]
> levels(data$variable)
[1] "SB" "FG" "ncRNA"
이제 일관된 형태의 이름으로 바뀐것을 확인할 수 있다. 이제 마지막으로 plot을 생성하면 된다.
> plot <- bwplot(value ~ variable | season, data=data)
> plot$ylab <- "Cups of Tea per day"
> print(plot)
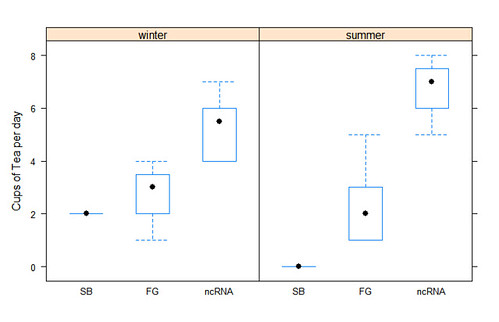
그려진 plot은 두개의 서로다른 계절로 분리되어 보여준다. bwplot에서 | season을 통해서 season 변수의 값으로 구분했기 때문이다.
Factored continuous data
마지막 예제는 categorical 변수에 대한 continuous data factored이다. 뭔 소린지. ^^' 여기서는 continuous_categorical.csv를 읽어 들인다.
> data <- read.csv("/path/to/file/continuous_categorical.csv")
> head(data)
water water.prod tea tea.prod hipflask hf.prod
1 0.4172023 33.99677 0.7731859 31.71567 1.1661047 24.90616
2 0.9628104 40.04022 0.5545423 29.11507 0.3830907 31.74964
3 1.3025050 40.78758 0.9033747 28.75205 1.0460207 29.64453
4 1.3352481 40.19776 1.2515750 28.68057 1.3909051 20.29845
5 0.8253107 38.38265 0.9861313 30.44975 0.2510354 31.51177
6 1.5136886 40.61841 0.9458123 29.50657 1.1346057 25.31571
이 데이터는 물(water), 차(tea), 포켓위스키에 담겨진(contents of a hipflask) 3개의 서로 다른 음료수를 보여주고 있다. 데이터는 두개의 continus 변수로, 음료에 따른 생산성과 categorical 인 음료의 종류를 보여주고 있다. 첫번째로 long 형태로 변환해 보자.
> water <- cbind(data[,1:2],drink="water")
> tea <- cbind(data[,3:4],drink="tea")
> hipflask <- cbind(data[,5:6],drink="hipflask")
데이터 셋을 3개로 나누고 음료의 종류 컬럼을 추가하였다.
> head(water)
water water.prod drink
1 0.4172023 33.99677 water
2 0.9628104 40.04022 water
3 1.3025050 40.78758 water
4 1.3352481 40.19776 water
5 0.8253107 38.38265 water
6 1.5136886 40.61841 water
> head(tea)
tea tea.prod drink
1 0.7731859 31.71567 tea
2 0.5545423 29.11507 tea
3 0.9033747 28.75205 tea
4 1.2515750 28.68057 tea
5 0.9861313 30.44975 tea
6 0.9458123 29.50657 tea
각각의 데이터 셋에 대해서 변수 이름이 맞지 않다. 각각을 volume과 productivity로 로 변경한다.
> col.names <- c("volume","productivity")
> names(water)[1:2] <- col.names
> names(tea)[1:2] <- col.names
> names(hipflask)[1:2] <- col.names
이제 3개의 데이터셋을 rbind를 이용해서 하나로 합친다.
> data <- rbind(water,tea,hipflask)
> head(data)
volume productivity drink
1 0.4172023 33.99677 water
2 0.9628104 40.04022 water
3 1.3025050 40.78758 water
4 1.3352481 40.19776 water
5 0.8253107 38.38265 water
6 1.5136886 40.61841 water
마지막으로 사용자 정의 panel(custom panel)을 생성해서 그래프를 그린다.
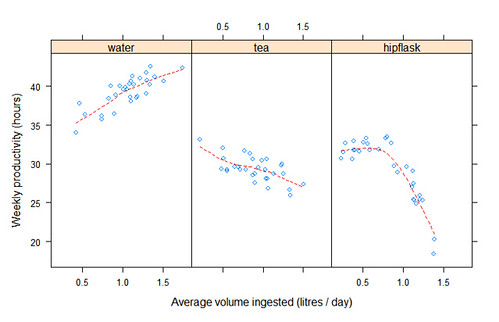
> plot <- xyplot(productivity ~ volume | drink, data=data)
> plot$xlab <- "Average volume ingested (litres / day)"
> plot$ylab <- "Weekly productivity (hours)"
> custom_panel <- function(x,y){
panel.xyplot(x,y)
panel.loess(x,y,col=”red”,lty=2)
}
> plot$panel <- custom_panel
> print(plot)
우선 "하루에 차(커피)를 얼마나 드십니까?" 라는 질문으로 시작하겠습니다. 이 질문에 마음속으로 대답을 하셨다면 이제 R package와 예제 데이터 파일(zip format)을 다운로드하시고 차한잔을 옆에 두고 천천히 읽어나가시기 바랍니다. ^^
여기서는 다음의 4가지 유형의 데이터를 그래프로 어떻게 표현하는지에 대해서 설명합니다.
1. Categorical data
2. Continuous data
3. Factored categorical data
4. Factored cotinuous data
Categorical data
첫번째로 Categorical data는 이름을 가지고 있으며, 숫자형이 아닌 값을 가지고 있는 경우입니다. 원형, 사각형, 삼각형같은 경우가 되겠죠. 또는 대, 중, 소와 같은 것도 카테고리 데이터에 속하겠습니다. 여기서는 system biology, Functional genomicsm Non-coding RNA의 각각 3가지 연구영역의 연구자들이 하루에 마시는 차의 횟수 데이터를 가지고 진행합니다.
categorical data 파일 categorical.csv를 읽어들인다.
> data <- read.csv("path/to/file/categorical.csv")
ls()를 통해서 data object가 읽어들여진것을 확인한다.
> ls()
[1] "data"
data object는 앞서 말한것과 같이 3개의 바이오인포매틱스 연구영역(이것이 category가 되겠죠)과 이영역의 연구자들이 하루에 얼마나 많은 양의 차를 마시는지에 대한 데이터가 있다.
> head(data)
Systems.biology Functional.genomics Non.coding.RNA
1 2 4 5
2 2 4 7
3 2 1 7
4 2 4 5
5 2 3 5
6 2 3 4
1,2,3....6이라고 씌어진 첫번째 컬럼은 행번호(row number)이며, 뒤이은 3개의 컬럼이 하루에 마시는 차의 양을 나타낸다. 언뜻 보더라도 Non-coding RNA 연구자들이 꽤 많이 마시는듯..??
자 그럼 categorical 데이터를 어떻게 가시화 시킬것인가? 첫번째로 해야할 일은 데이터를 다른 포맷으로 변경하는 일이다. 첫번째 컬럼에 System biology가 있고 그 이후로 다른 영역의 데이터가 존재하는 형태이다. 이러한 형태를 지금부터 "wide"라고 하겠다. 만약 100개의 연구영역이 존재한다면 100개의 컬럼으로 구성된 넓은 형태로 보여지기 때문이다. 따라서 "long" 포맷의 길다란 모양으로 데이터를 변형시키도록 하겠다.
wide를 long 형태로 변형하기 위해서는 R package의 reshape 패키지를 사용한다. reshape는 R에 기본적으로 포함되지 않기 때문에 요기를 참고해서 패키지를 설치한다. 이제 설치한 패키지를 로드한다.
> library(reshape)
그런다음 다음의 명령어로 reshape를 수행한다.
> data <- melt(data,measure.var=c("Systems.biology","Functional.genomics","Non.coding.RNA"))
그러면, 다음과 같이 3개의 변수로 구분된 데이터를 long 형태로 확인할 수 있다.
> head(data)
variable value
1 Systems.biology 2
2 Systems.biology 2
3 Systems.biology 2
4 Systems.biology 2
5 Systems.biology 2
6 Systems.biology 2
첫번째 컬럼은 bioinformatics 타입, 두번째 컬럼은 하루에 먹는 차의 양 형태로 보여준다. 이제 phylogenetics와 같은 다른 연구 영역을 추가하더라도 열만 추가 된다.
이제 어떤 영역의 연구자들이 가장 많이 차를 마시는지 plot을 이용하여 데이터를 보여주도록 하자. 여기서는 lattice라는 R 패키지를 이용할 것이다. lattice 패키지는 기본적으로 R에 포함되어 있기 때문에 별도의 패키지 설치 과정없이 다음과 같이 호출하면 된다.
> library(lattice)
categorical 데이터를 표현하기 위한 가장 좋은 plot은 box and whisker plot이다. lattice의 bwplot(box and whisker plot)을 이용하여 plot을 생성하자.
> plot <- bwplot(value ~ variable, data = data)
> plot$ylab <- "Cups of Tea per day"
> print(plot)
bwplot의 value ~ variable은 R에서의 값,value(즉 하루에 먹은 차의 양)와 변수,variable(바이오인포매틱스 연구분야)를 위미한다. 그 다음의 data=data의 의미는 R에서의 plot을 그리기 위한 데이터가 R 객체 data에 저장되어있다는 것을 의미한다. 그 결과를 plot이라는 R 객체에 넣어둔다. 그 다음 줄인 plot$ylab은 y축의 라벨을 cups of tea per day로 지정하는 것이다. 마지막으로는 print(plot)을 이용해서 plot 객체를 그래픽 디바이스로 출력하라는 의미이다.
이제 이 그래프 하나로 하루에 몇잔의 차를 마시는지 알기 쉽게 볼 수 있게 되었다. system biologists는 정확하게 하루에 2잔씩, functional genomists는 1~5잔을, non-coding RNA-ist는 최대 7잔까지 ^^
Continuous data
앞서서 각 연구 분야별(categorical data) 하루 마시는 차의 양에 대해서 그래프를 그려봤는데, 이번에는 Continuous data에 대해서 알아보도록 하겠습니다. continuous 데이터는 숫자 형식의 데이터이다. 앞서서와 마찬가지로 파일을 읽어 들인다.
> data <- read.csv("path/to/file/continuous.csv")
> head(data)
distance productivity
1 54.86337 35.05450
2 53.97946 35.66953
3 53.74379 35.00325
4 41.41431 35.23826
5 73.96309 32.07927
6 58.19178 33.35028
이 데이터는 바이오인포매틱스 연구자와 차를 만드는 방까지의 거리와 한 주동안의 생산성을 나타내고 있다. 이 데이터는 이전에 말한 두개의 컬럼으로 이루어져 long 형태의 데이터포맷으로 잘 이루어져 있다.
이러한 두개의 continuous 변수를 가장 잘 비교하기 위한 위한 벙법은 xyplot으로 각각을 축으로 나타내면 된다. 생산성에 대한 "차를 만드는 방까지의 거리"에 대하여 이전과 마찬가지 방법으로 plot을 생성한다. 이때 xyplot 함수와 각각의 x, y축에 대한 라벨을 생성한다.
> plot <- xyplot(productivity ~ distance, data=data)
> plot$xlab <- "Distance to tea making area (feet)"
> plot$ylab <- "Weekly productivity (hours)"
> print(plot)
위의 결과를 통해 차를 만드는 장소가 가까울수록 생산성이 좋아진다는 것을 알 수 있다. 이렇게 만들어진 plot에 (x,y)축 안쪽에 선을 하나 추가하기 위해 "panel"을 한 생성한다. panle.xyplot을 사용하여 사용자 정의 panel을 추가한다.
> custom_panel_lm <- function(x,y) {
panel.xyplot(x,y)
panle.lmline(x,y)
}
> plot$panel <- custom_panel_lm
> print(plot)
첫번째 function(x,y) x와 y(x,y는 continuous 변수)를 인자로 같는 함수를 정의하고 있다. 이 함수는 두개의 메소드를 호출하고 있는데, 첫번째는 panel.xyplot 함수로 plot을 그리는 함수, 두번째는 x,y 인자를 가지고 선형 추세선을 그린다. 이렇게 만들어진 함수를 이전 plot에 panel을 추가하고 print하면 된다.
이제 선을 통해서 거리와 생산성과의 관계를 좀더 확실하게 보여준다. 그럼 데이터의 좀더 정확한(?) 동향을 위해서 좀 울퉁불퉁한 선을 추가하도록 하자.
> custom_panel_loess <- function(x,y) {
panel.xyplot(x,y)
panle.loess(x,y)
}
> plot$panel <- custom_panel_loess
> print(plot)
Factored categorical data
지금까지 연구자들이 얼마나 많은 양의 차를 마시는지에 대한 추세(??추이, 경향)를 봤다. 그러나 계절에 따라서 이러한 추세를 보고자 한다면, 여름에 비해서 겨울은 어떠한지 말이다. 이것에 대한 데이터가 categorical_categorical.cvs에 있다.
> data <- read.csv("path/to/file/categorical_categorical.csv")
> head(data)
SB FG ncRNA SB.1 FG.1 ncRNA.1
1 2 2 4 0 1 7
2 2 2 5 0 2 6
3 2 4 6 0 5 8
4 2 4 4 0 3 7
5 2 2 5 0 1 6
6 2 1 4 0 2 8
자 wide형태이 데이터 형태를 가지고 있으며, 첫번째 3개의 컬럼은 겨울철 데이터를 나머지 3개의 컬럼은 여름철의 데이터를 나타내고 있다. 첫번째 categorical 데이터는 연구분야(area of research), 두번째 category는 계절(season)이 된다.
> winter <- data[,1:3]
> summer <- data[,4:6]
> winter <- melt(winter,measure.var=c(”SB”,”FG”,”ncRNA”))
> summer <- melt(summer,measure.var=c(”SB.1″,”FG.1″,”ncRNA.1″))
첫번째로는 long 형태로 바꾸는 작업을 수행해야 한다. 여기서 3개의 컬럼이 필요하다. 하루동안 마시는 차의 양, 연구분야, 계절의 3개의 변수를 사용할것이기 때문이다.
> head(winter)
variable value
1 SB 2
2 SB 2
3 SB 2
4 SB 2
5 SB 2
6 SB 2
> head(summer)
variable value
1 SB.1 0
2 SB.1 0
3 SB.1 0
4 SB.1 0
5 SB.1 0
6 SB.1 0
이제 별도의 계절 변수를 추가하기로 한다. 이 변수는 새로운 컬럼으로 등록된다.
> summer <- cbind(summer,season="summer")
> winter <- cbind(winter,season="winter")
cbind는 새로운 컬럼을 추가하는 명령으로, season이라는 컬럼을 만들고 여기에 summer와 winter 값을 각각 넣었다. 다시 winter와 summber 객체를 보면 다음과 같다.
> head(summer)
variable value season
1 SB.1 0 summer
2 SB.1 0 summer
3 SB.1 0 summer
4 SB.1 0 summer
5 SB.1 0 summer
6 SB.1 0 summer
> head(winter)
variable value season
1 SB 2 winter
2 SB 2 winter
3 SB 2 winter
4 SB 2 winter
5 SB 2 winter
6 SB 2 winter
이제 새로운 season 컬럼이 생긴것을 확인할 수 있다. 마지막으로 두개의 데이터 세트를 함께 합쳐야 한다.
> data <- rbind(winter,summer)
rbind 는 새로운 행으로 묶으라는 명령이다. 이제 summer 데이터 아래에 winter 데이터가 합쳐졌다. 이제 한가지만 하면 plot을 생성할 수 있다. 여기서 summer 데이터에는 각 연구분야.1 형태로 .1이 붙어 있다. leveles로 변수 컬럼을 살펴보면 다음과 같이 .1이 붙어 있다.
> levels(data$variable)
[1] "SB" "FG" "ncRNA" "SB.1" "FG.1" "ncRNA.1"
이제 .1을 제거하고 처음 나오는 3개의 변수를 대체해보도록 하자.
> levels(data$variable)[4:6] <- levels(data$variable)[1:3]
> levels(data$variable)
[1] "SB" "FG" "ncRNA"
이제 일관된 형태의 이름으로 바뀐것을 확인할 수 있다. 이제 마지막으로 plot을 생성하면 된다.
> plot <- bwplot(value ~ variable | season, data=data)
> plot$ylab <- "Cups of Tea per day"
> print(plot)
그려진 plot은 두개의 서로다른 계절로 분리되어 보여준다. bwplot에서 | season을 통해서 season 변수의 값으로 구분했기 때문이다.
Factored continuous data
마지막 예제는 categorical 변수에 대한 continuous data factored이다. 뭔 소린지. ^^' 여기서는 continuous_categorical.csv를 읽어 들인다.
> data <- read.csv("/path/to/file/continuous_categorical.csv")
> head(data)
water water.prod tea tea.prod hipflask hf.prod
1 0.4172023 33.99677 0.7731859 31.71567 1.1661047 24.90616
2 0.9628104 40.04022 0.5545423 29.11507 0.3830907 31.74964
3 1.3025050 40.78758 0.9033747 28.75205 1.0460207 29.64453
4 1.3352481 40.19776 1.2515750 28.68057 1.3909051 20.29845
5 0.8253107 38.38265 0.9861313 30.44975 0.2510354 31.51177
6 1.5136886 40.61841 0.9458123 29.50657 1.1346057 25.31571
이 데이터는 물(water), 차(tea), 포켓위스키에 담겨진(contents of a hipflask) 3개의 서로 다른 음료수를 보여주고 있다. 데이터는 두개의 continus 변수로, 음료에 따른 생산성과 categorical 인 음료의 종류를 보여주고 있다. 첫번째로 long 형태로 변환해 보자.
> water <- cbind(data[,1:2],drink="water")
> tea <- cbind(data[,3:4],drink="tea")
> hipflask <- cbind(data[,5:6],drink="hipflask")
데이터 셋을 3개로 나누고 음료의 종류 컬럼을 추가하였다.
> head(water)
water water.prod drink
1 0.4172023 33.99677 water
2 0.9628104 40.04022 water
3 1.3025050 40.78758 water
4 1.3352481 40.19776 water
5 0.8253107 38.38265 water
6 1.5136886 40.61841 water
> head(tea)
tea tea.prod drink
1 0.7731859 31.71567 tea
2 0.5545423 29.11507 tea
3 0.9033747 28.75205 tea
4 1.2515750 28.68057 tea
5 0.9861313 30.44975 tea
6 0.9458123 29.50657 tea
각각의 데이터 셋에 대해서 변수 이름이 맞지 않다. 각각을 volume과 productivity로 로 변경한다.
> col.names <- c("volume","productivity")
> names(water)[1:2] <- col.names
> names(tea)[1:2] <- col.names
> names(hipflask)[1:2] <- col.names
이제 3개의 데이터셋을 rbind를 이용해서 하나로 합친다.
> data <- rbind(water,tea,hipflask)
> head(data)
volume productivity drink
1 0.4172023 33.99677 water
2 0.9628104 40.04022 water
3 1.3025050 40.78758 water
4 1.3352481 40.19776 water
5 0.8253107 38.38265 water
6 1.5136886 40.61841 water
마지막으로 사용자 정의 panel(custom panel)을 생성해서 그래프를 그린다.
> plot <- xyplot(productivity ~ volume | drink, data=data)
> plot$xlab <- "Average volume ingested (litres / day)"
> plot$ylab <- "Weekly productivity (hours)"
> custom_panel <- function(x,y){
panel.xyplot(x,y)
panel.loess(x,y,col=”red”,lty=2)
}
> plot$panel <- custom_panel
> print(plot)
반응형
공지사항
최근에 올라온 글