
티스토리 뷰
반응형
생물정보학에서의 서열 유사성 검색의 중요성은 굳이 설명하지 않아도 다들 이해하시리라 믿는다. 여기서는 String Match라는 관점에서 서열 데이터(text)로 부터 주어진 서열 찾는 Suffix Tree 알고리즘과 이 알고리즘을 GPU를 통해서 구현하는 방법에 대해서 알아보고자 한다.
GPU(Graphics Processing Unit)는 무엇인가?
간단하게 말하면 컴퓨터에 있는 그래픽 카드의 CPU라고 생각하면 될것이다. 요즘 게임들은 3D와 실사와 정말 유사한 화면을 제공하는데, 이러한 것들을 CPU가 아닌 그래픽 카드의 GPU에서 처리하게 함으로써 좀 더 빠르게 게임을 할 수 있는 환경을 제공하는 것이다. 그런데 이 GPU의 아키텍처의 특성상 이것만 하기에는 너무 아깝기 때문에 범용적인 수치연산과 응용계산에서도 사용할 수 있도록 한 것이 바로 GPGPU(범용계산GPU, General-Purpose computation on GPUs)가 되겠다.

이것에서 좀더 발전해서 GPGPU를 통해서 일반적인 응용계산을 수행할 수 있는 프로그래밍을 할 수 있는 프레임워크가 바로 CUDA(Compute Unified Device Architecture)인 것이다. 단순하게 말해서 프로그래머는 엔비디아 그래픽 카드를 컴퓨터에 장착하고 CUDA를 설치한 후 C언어로 부동소수점 연산을 많이 하는 프로그래밍을 하면 엄청난 속도 향상을 얻을 수 있는 것이다.
GPGPU와 CUDA에서의 병렬 처리
앞서도 잠깐 언급했지만, GPU는 그래픽 처리를 위한 것으로 범용적인 용도로 사용하기에 무리가 있기 때문에 GPGPU라는 범용의 GPU가 탄생하기에 이르렀고, 엔비디아는 이러한 GPU의 스트림 프로세서를 활용하여 그래픽 처리 뿐만 아니라 쓰레드 단위의 병렬 처리가 가능한 CUDA에 이르게 된것이다.
CUDA는 메모리와 ALU 사이의 Parallel Data Cache를 통해서 데이터를 여러개의 ALU에서 사용함으로서 쓰레드 단위의 병렬처리를 수행하게 된다. 이를 통해서 데스크탑이나 노트북을 가지고도 슈퍼컴퓨터에 맞먹는 컴퓨팅 파워를 제공할 수 있는 시대가 다가오고 있다. 이미 엔비디아에서는 여러 분야에서의 활용 사례를 통해 그 성능을 입증하고 있다. 이제 기상관측, 물리 연산, 바이오인포매틱스 등 다양한 분야(물론 슈퍼컴퓨터가 필요한 모든 분야)에서 CPU에 비해 몇백배 빠른 연산 처리가 가능해지고 있다. 물론 데스크탑 하나로도 ^^;;
Bioinformatics에서의 활용
적어도 연구비가 부족한(?) 대학의 연구실이나 개인들이 비교적 저렴한 비용으로 슈퍼컴퓨터의 성능에는 미치지 않겠지만, 비교적 만족스러울 만한 성능을 얻을 수 있는 길이 열리게 된 것이다. 물론 기존의 MPI와 같은 복잡한? 과정보다 비교적 널리 사용될? CUDA 환경을 이용할 수 있게 되는것 또한 무시 못할 것이다.(아무리 성능도 좋다 하더라도 그 사용자 층에 얇다면 성능이 좀 떨어지더라도 사용자 층이 두터운 것이 향후 개발이나 문제에 무딪혔을때 여러모로 유용한 것은 당연한 일이다) 따라서 CUDA 환경은 이러한 여러가지 잇점을 태생적으로 타고 태어났으며, 그 반향은 향후 병렬 컴퓨팅에 많은 도움을 줄 것이라고 믿는다.
그럼 리눅스 클러스터나 슈퍼컴퓨터를 사용하기 어려운 Bioinformatics 관련 연구소나 대학의 일차적인 컴퓨팅 파워는 비교적 값싼 CUDA 환경으로 해결됐다. 이제 남은건 실제 이를 활용한 병렬 프로그램이 되겠다. 그럼 여기서는 Suffix Tree를 이용해서 서열의 유사성 검색에 활용해 보도록 하자.
Suffix Tree 알고리즘(문자열 매칭 알고리즘)을 통한 서열 매칭
Suffix Tree는 문자열 매칭에서 유용한 알고리즘으로 주어진 문자 S에 대해서 모든 suffix를 가지고 있는 트리를 생성해서 검색하는 방법이다.
CDUA로 구현하는 서열 검색
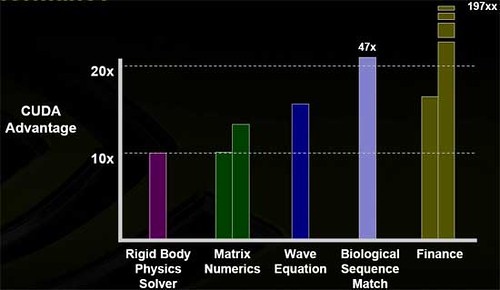
이제 Suffix Tree를 CUDA를 통해 병렬처리 할 수 있도록 하면, 앞서 nvida에서 말한 47배의 속도 향상이 있겠죠 ^^;; 이 부분은 아직 CUDA에 대해서 공부 좀 하고 어느 부분에서 병렬화 처리가 가능한지,,, 어떻게 구현해야 하는지 차근 차근 포스팅 해야겠습니다.
GPU(Graphics Processing Unit)는 무엇인가?
간단하게 말하면 컴퓨터에 있는 그래픽 카드의 CPU라고 생각하면 될것이다. 요즘 게임들은 3D와 실사와 정말 유사한 화면을 제공하는데, 이러한 것들을 CPU가 아닌 그래픽 카드의 GPU에서 처리하게 함으로써 좀 더 빠르게 게임을 할 수 있는 환경을 제공하는 것이다. 그런데 이 GPU의 아키텍처의 특성상 이것만 하기에는 너무 아깝기 때문에 범용적인 수치연산과 응용계산에서도 사용할 수 있도록 한 것이 바로 GPGPU(범용계산GPU, General-Purpose computation on GPUs)가 되겠다.
Geforce 8800 GTS
이것에서 좀더 발전해서 GPGPU를 통해서 일반적인 응용계산을 수행할 수 있는 프로그래밍을 할 수 있는 프레임워크가 바로 CUDA(Compute Unified Device Architecture)인 것이다. 단순하게 말해서 프로그래머는 엔비디아 그래픽 카드를 컴퓨터에 장착하고 CUDA를 설치한 후 C언어로 부동소수점 연산을 많이 하는 프로그래밍을 하면 엄청난 속도 향상을 얻을 수 있는 것이다.
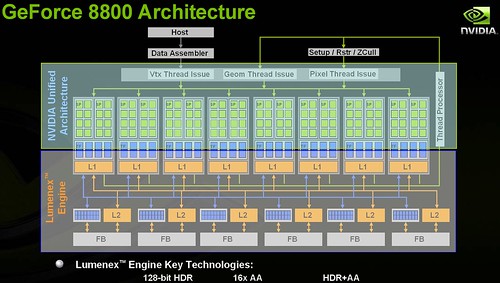
Geforce 8800 Architecture - 중간의 녹색은 스트림 프로세서가 16개가 한개의 그룹으로 되어있다.

GPGPU와 CUDA에서의 병렬 처리
앞서도 잠깐 언급했지만, GPU는 그래픽 처리를 위한 것으로 범용적인 용도로 사용하기에 무리가 있기 때문에 GPGPU라는 범용의 GPU가 탄생하기에 이르렀고, 엔비디아는 이러한 GPU의 스트림 프로세서를 활용하여 그래픽 처리 뿐만 아니라 쓰레드 단위의 병렬 처리가 가능한 CUDA에 이르게 된것이다.
CUDA를 이용한 각 분야의 속도 향상(일반 CPU와 비교했을 경우)
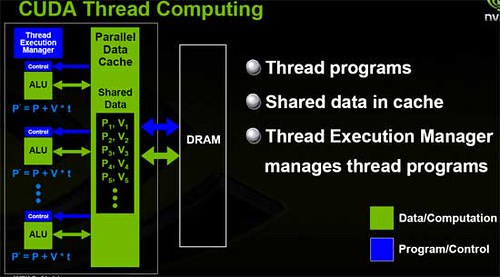
CUDA는 메모리와 ALU 사이의 Parallel Data Cache를 통해서 데이터를 여러개의 ALU에서 사용함으로서 쓰레드 단위의 병렬처리를 수행하게 된다. 이를 통해서 데스크탑이나 노트북을 가지고도 슈퍼컴퓨터에 맞먹는 컴퓨팅 파워를 제공할 수 있는 시대가 다가오고 있다. 이미 엔비디아에서는 여러 분야에서의 활용 사례를 통해 그 성능을 입증하고 있다. 이제 기상관측, 물리 연산, 바이오인포매틱스 등 다양한 분야(물론 슈퍼컴퓨터가 필요한 모든 분야)에서 CPU에 비해 몇백배 빠른 연산 처리가 가능해지고 있다. 물론 데스크탑 하나로도 ^^;;
CUDA에서의 병렬처리
Bioinformatics에서의 활용
적어도 연구비가 부족한(?) 대학의 연구실이나 개인들이 비교적 저렴한 비용으로 슈퍼컴퓨터의 성능에는 미치지 않겠지만, 비교적 만족스러울 만한 성능을 얻을 수 있는 길이 열리게 된 것이다. 물론 기존의 MPI와 같은 복잡한? 과정보다 비교적 널리 사용될? CUDA 환경을 이용할 수 있게 되는것 또한 무시 못할 것이다.(아무리 성능도 좋다 하더라도 그 사용자 층에 얇다면 성능이 좀 떨어지더라도 사용자 층이 두터운 것이 향후 개발이나 문제에 무딪혔을때 여러모로 유용한 것은 당연한 일이다) 따라서 CUDA 환경은 이러한 여러가지 잇점을 태생적으로 타고 태어났으며, 그 반향은 향후 병렬 컴퓨팅에 많은 도움을 줄 것이라고 믿는다.
그럼 리눅스 클러스터나 슈퍼컴퓨터를 사용하기 어려운 Bioinformatics 관련 연구소나 대학의 일차적인 컴퓨팅 파워는 비교적 값싼 CUDA 환경으로 해결됐다. 이제 남은건 실제 이를 활용한 병렬 프로그램이 되겠다. 그럼 여기서는 Suffix Tree를 이용해서 서열의 유사성 검색에 활용해 보도록 하자.
Suffix Tree 알고리즘(문자열 매칭 알고리즘)을 통한 서열 매칭
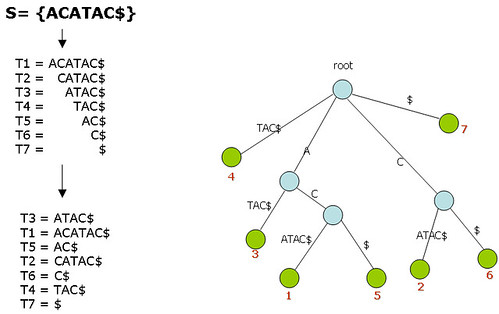
Suffix Tree는 문자열 매칭에서 유용한 알고리즘으로 주어진 문자 S에 대해서 모든 suffix를 가지고 있는 트리를 생성해서 검색하는 방법이다.
Suffix Tree
이제 "ATA"를 찾아보면, 다음과 같다 Suffix Tree는 O(n2)의 복잡도를 가진다.
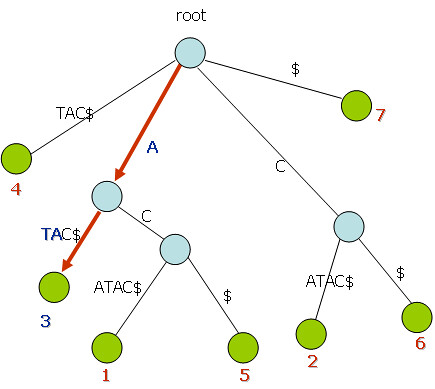
Suffix Tree Search
CDUA로 구현하는 서열 검색
이제 Suffix Tree를 CUDA를 통해 병렬처리 할 수 있도록 하면, 앞서 nvida에서 말한 47배의 속도 향상이 있겠죠 ^^;; 이 부분은 아직 CUDA에 대해서 공부 좀 하고 어느 부분에서 병렬화 처리가 가능한지,,, 어떻게 구현해야 하는지 차근 차근 포스팅 해야겠습니다.
반응형
공지사항
최근에 올라온 글