
티스토리 뷰
반응형
어제 오늘 Hadoop Cluster를 설정을 하고는 MapReduce 예제들을 돌려보고 있다.(jetty 웹서버가 인터넷에 연결이 되지 않으면 뭔 j2ee 네임스페이스를 찾을 수 없다고 에러를 내는 바람에 이거 찾느라고 어제 하루는 다 보내 버렸다.) 우선 RandomWriter를 통해서 30GB의 입력데이터로 사용할 데이터를 생성했다. 1GB씩 총 30개가 생성되었다.
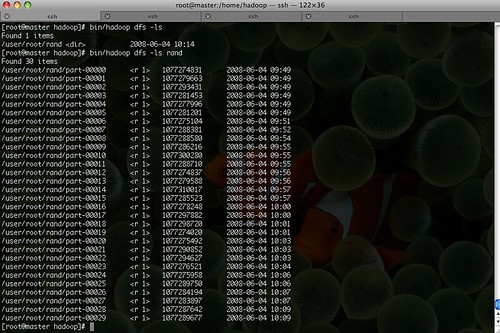
RandomWriter를 통해 생성된 데이터
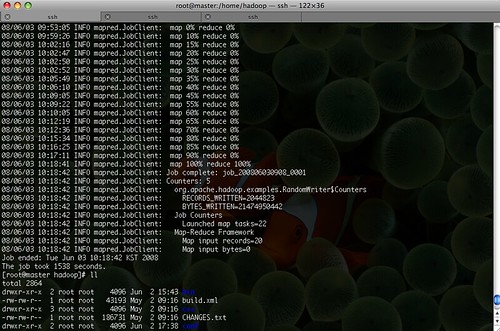
총 1538초 약 26분정도의 시간이 소요되었다.(테스트는 총 3대의 DataNode에서 수행,,)
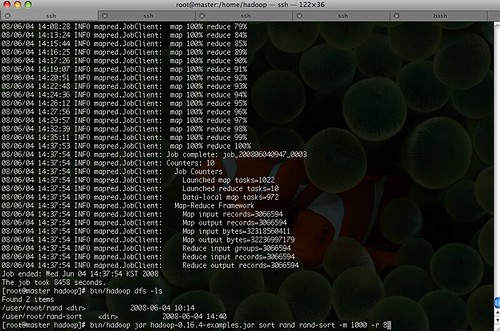
map 1,000 Reduce 8으로 주고 sort 실행
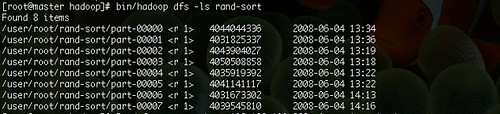
sort 결과 파일
이전에 돌려본 wordcount 예제에서도 결과는 모두 Reduce의 갯수 만큼 생성되었다. 뭐 아직까지는 Hadoop에 들어있는 예제들을 통해서 실제 작업에 사용할만한지 계속 테스트중이다. 어느정도 만족한 결과들이 보이면 바로 실전에 투입할 수 있도록 ^^;; ㅋㅋㅋ
RandomWriter를 통해 생성된 데이터
총 1538초 약 26분정도의 시간이 소요되었다.(테스트는 총 3대의 DataNode에서 수행,,)
이 입력데이터를 가지고 역시 예제 Sort를 수행하였다. 처음에는 Map과 Reduce의 갯수를 지정하지 않고 다음과 같이 기본 명령만을 주고 수행하였다.
$ bin/haddop jar hadoop-*-example.jar sort rand rand-sort
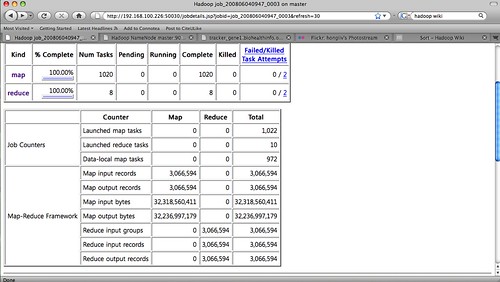
결과는 outofmemory를 중간중간 내뱉다가는 결국에는 fail이 나고 말았다. 하둡의 퍼포먼스(삽질기)를 보고는 Map의 갯수를 1,000개 Reduce 갯수를 8로 주고 다시 실행해 보았다.
$ bin/haddop jar hadoop-*-example.jar sort rand rand-sort
결과는 outofmemory를 중간중간 내뱉다가는 결국에는 fail이 나고 말았다. 하둡의 퍼포먼스(삽질기)를 보고는 Map의 갯수를 1,000개 Reduce 갯수를 8로 주고 다시 실행해 보았다.
map 1,000 Reduce 8으로 주고 sort 실행
그 결과 위에 보이는 것과 같이 총 8,458초 약 2시간20분 정도 시간이 걸려서 sort를 마무리 했다. 그런데 sort를 수행하면 결과는 하나의 파일에 일목요연하게 sort의 결과가 나와야 하건만,,, 결과파일은 다음과 같이 Reduce의 갯수만큼 생성되었다.
sort 결과 파일
RandomWrite를 통해 생성된 데이터를 입력으로 받아 sort한 결과
이전에 돌려본 wordcount 예제에서도 결과는 모두 Reduce의 갯수 만큼 생성되었다. 뭐 아직까지는 Hadoop에 들어있는 예제들을 통해서 실제 작업에 사용할만한지 계속 테스트중이다. 어느정도 만족한 결과들이 보이면 바로 실전에 투입할 수 있도록 ^^;; ㅋㅋㅋ
반응형
공지사항
최근에 올라온 글