
티스토리 뷰
반응형
저번주는 MapReduce를 Streaming 방식으로 작성된것을 실행해 보았따. Writing An Hadoop MapReduce Program In Python을 보면 WordCount 예제가 Python으로 작성되어 있다. 또 URL을 통해 해당 URL을 <title>제목을 가져오는 Python 예제도 있다. 그런데,, 하나의 노드로 마스터와 네임노드를 구성해서 할 경우에는 잘 되었는데,, 막상 15노드로 Hadoop 클러스터를 구성하고 실행을 하는데,, Map 작업의 결과는 잘 나오는데 Reduce에서 결과 레코드가 모두 0 즉, 결과가 없다. 뭐가 잘못되었는 전혀 감이 오지 않아서Streaming을 포기하고 결국 Java로 하기로 했다.
그래서 오늘은 깔끔하게 Streaming을 잊고,,, 저번에 잠깐 살펴본 Running Hadoop MapReduce on Amazon EC2 and Amazon S3를 실행해 보기로 했다. 저번 포스팅에서도 잠깐 언급했듯이 웹서버로그를 가져다가 요일별로 잘라서 해당 요일에 방문자 얼마나 왔는지 보는 과정이다.
우선 웹서버 로그가 필요했다. 그것도 많이,,, 웹서버들을 몽땅 뒤졌도 고작 99MB였다. 실제적으로 사용하는 큰 데이터를 돌려보고 뭔가 해볼려고 했더니 우선 포기하고, 99MB라도 데이터는 우리웹서버의 데이터니까,, 한번 돌려보는것도 괜찮을 듯 했다. 나중에 큰 데이터는 뻥튀기를 해서 테스트 해 보면 되는까, 우선 실제 데이터로 돌려보기로 했다.
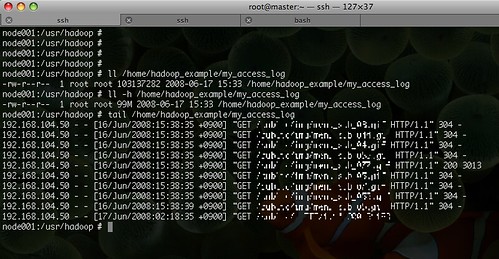
몽땅 긁었지만,,, 99MB
준비된 로그를 copyFromLocal을 통해 HDFS에 놓는다.


이제 웹서버 로그를 파싱해서 요일별로 나누고 묶는 프로그램을 작성한다. 우선 전체 소스코드는 여기(AccessLogFileAnalyzer.java)에서 볼 수 있다. 앞서 언급한 Amazon의 글은 Hadoop 버전이 낮아서 0.17버전에 맞도록 몇가지 수정을 한 코드이다.
웹서버의 로그에서 패턴매칭을 통해 날짜 부분(16/Jun/2008:15:38:35 +0900)만을 가져온 후 이를 월요일부터 00시00분을 기준으로 몇분이 경과했는지를 계산한다. 6월16일은 월요일이고 15시38분이니까,, 기준인 월요일 0시0분부터 938분이 경과했다. 이런 과정으로 모든 날짜에 대해서 요일별로 구분하고 월요일로부터 몇분이 경과했는지(minute-in-week slot) 계산한다. 이때 joda 라이브러리를 사용해서 날짜를 계산하는데 사용하는데 자꾸만 Jun부분에서 에러가 발생했다. Locale이 KO이기 때문에 Jun은 모른단다,,,^^;; 따라서 Hadoop서버의 Locale이 KO인 경우에는 Locale.setDefault(Locale.ENGLISH)를 추가해서 해당 에러를 피해가야 한다.
Map 작업에서는 위와 같이 (<minute-in-week slot>, <1>) 의 Key-Value 쌍으로 만드는 작업을 수행한다. 이제 Reduce에서는 해당 minute-in-week의 총 합을 구해서 (<minute-in-week slot>, <total hits>)으로 만들게 된다.
최종 결과는 다음과 같은 형식으로 나오게 된다.
이제 작성된 AccessLogFileAnalyzer.java를 컴파일한 후 jar파일로 압축하여 실행하면 된다.

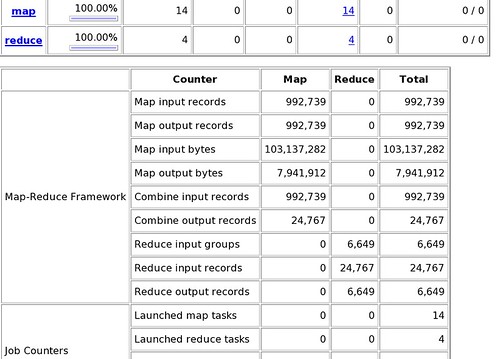
작업을 마친 후에는 다음과 같이 결과 파일을 확인 할 수 있다. Reduce 작업에서 sort가 되었기 때문에,,, 월요일 12시 1분에 들어온게 672건 있구나,,,
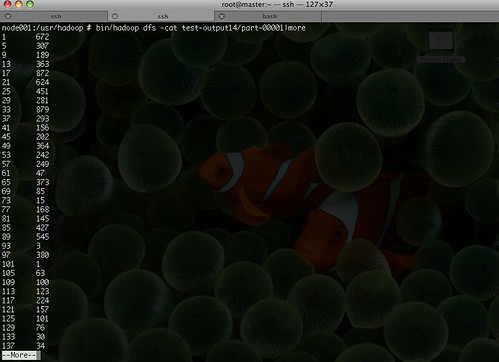
이제 HDFS상의 결과파일을 로컬파일시스템으로 가져와서 해당 데이터를 가지고 R을 통해서 plot을 생성하는 작업이 남았다. dfs의 -copyToLocal을 통해서 해당 데이터를 가져온다.
R을 실행하고 plot을 생성한다.
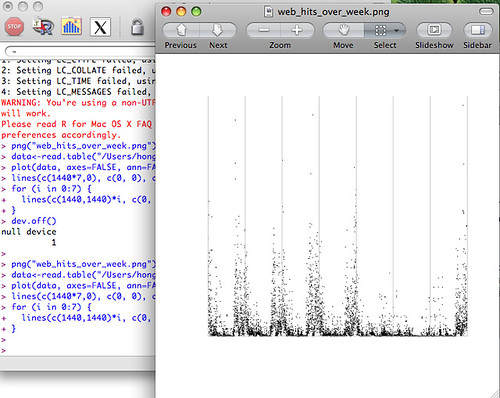
각 실선 사이는 월~일요일을 나타낸다. 금,토요일이 방문자가 적은편이고 왜케 새벽에들 들어온데,,, 실선부근은 새벽시간대에 가까운건데,,, 뭔가 잘못됐나?? 주로 새벽시간대에 봇들이 돌아다닌다... 고로 이 웹서버에는 사람들이 방문하는 것보다는 봇이 더 많다... 뭐 이정도 ㅋㅋㅋ
지금까지 Hadoop을 이용해서 로그를 분석하는 과정을 보았는데,,, 대용량의 로그 데이터를 기반으로 어느 정도의 속도를 내는지 체크하는 일만 남았다. 이 데이터를 몇백GB로 부풀려서 얼마만큼 Hadoop이 속도를 내는지 몹시 궁금해진다.
IBM의 Many Eyes에 결과데이터를 시각화 해보았다. Many Eyes는 자신의 데이터를 올리고 이를 손쉽게? 시각화해주는 사이트로 어떠한 데이터를 어떠한 방식으로 시각화해야 할지에 대한 좋은 아이디어를 얻을 수 있다.
그래서 오늘은 깔끔하게 Streaming을 잊고,,, 저번에 잠깐 살펴본 Running Hadoop MapReduce on Amazon EC2 and Amazon S3를 실행해 보기로 했다. 저번 포스팅에서도 잠깐 언급했듯이 웹서버로그를 가져다가 요일별로 잘라서 해당 요일에 방문자 얼마나 왔는지 보는 과정이다.
우선 웹서버 로그가 필요했다. 그것도 많이,,, 웹서버들을 몽땅 뒤졌도 고작 99MB였다. 실제적으로 사용하는 큰 데이터를 돌려보고 뭔가 해볼려고 했더니 우선 포기하고, 99MB라도 데이터는 우리웹서버의 데이터니까,, 한번 돌려보는것도 괜찮을 듯 했다. 나중에 큰 데이터는 뻥튀기를 해서 테스트 해 보면 되는까, 우선 실제 데이터로 돌려보기로 했다.
몽땅 긁었지만,,, 99MB
준비된 로그를 copyFromLocal을 통해 HDFS에 놓는다.
이제 웹서버 로그를 파싱해서 요일별로 나누고 묶는 프로그램을 작성한다. 우선 전체 소스코드는 여기(AccessLogFileAnalyzer.java)에서 볼 수 있다. 앞서 언급한 Amazon의 글은 Hadoop 버전이 낮아서 0.17버전에 맞도록 몇가지 수정을 한 코드이다.
192.168.104.50 - - [16/Jun/2008:15:38:35 +0900] "GET /public/img/menu_sub_03.gif HTTP/1.1" 304 -
192.168.104.50 - - [16/Jun/2008:15:38:35 +0900] "GET /public/img/menu_sub_044.gif HTTP/1.1" 304 -
192.168.104.50 - - [16/Jun/2008:15:38:35 +0900] "GET /public/img/menu_sub_04.gif HTTP/1.1" 304 -웹서버의 로그에서 패턴매칭을 통해 날짜 부분(16/Jun/2008:15:38:35 +0900)만을 가져온 후 이를 월요일부터 00시00분을 기준으로 몇분이 경과했는지를 계산한다. 6월16일은 월요일이고 15시38분이니까,, 기준인 월요일 0시0분부터 938분이 경과했다. 이런 과정으로 모든 날짜에 대해서 요일별로 구분하고 월요일로부터 몇분이 경과했는지(minute-in-week slot) 계산한다. 이때 joda 라이브러리를 사용해서 날짜를 계산하는데 사용하는데 자꾸만 Jun부분에서 에러가 발생했다. Locale이 KO이기 때문에 Jun은 모른단다,,,^^;; 따라서 Hadoop서버의 Locale이 KO인 경우에는 Locale.setDefault(Locale.ENGLISH)를 추가해서 해당 에러를 피해가야 한다.
<0, 192.168.0.5 - - [22/Aug/2005:22:07:52 +0000] "GET / HTTP/1.1" 200 1722> -> <1387, 1>
<71, 192.168.0.5 - - [22/Aug/2005:22:07:52 +0000] "GET /styles/layout.css HTTP/1.1" 200 2187> -> <1387, 1>
<159, 192.168.0.5 - - [22/Aug/2005:22:08:00 +0000] "GET /projects.html HTTP/1.1" 200 40247> -> <1388, 1>
Map 작업에서는 위와 같이 (<minute-in-week slot>, <1>) 의 Key-Value 쌍으로 만드는 작업을 수행한다. 이제 Reduce에서는 해당 minute-in-week의 총 합을 구해서 (<minute-in-week slot>, <total hits>)으로 만들게 된다.
<1387, (1, 1)> -> <1387, 2>
<1388, (1)> -> <1388, 1>최종 결과는 다음과 같은 형식으로 나오게 된다.
1387 2
1388 1이제 작성된 AccessLogFileAnalyzer.java를 컴파일한 후 jar파일로 압축하여 실행하면 된다.
작업을 마친 후에는 다음과 같이 결과 파일을 확인 할 수 있다. Reduce 작업에서 sort가 되었기 때문에,,, 월요일 12시 1분에 들어온게 672건 있구나,,,
이제 HDFS상의 결과파일을 로컬파일시스템으로 가져와서 해당 데이터를 가지고 R을 통해서 plot을 생성하는 작업이 남았다. dfs의 -copyToLocal을 통해서 해당 데이터를 가져온다.
R을 실행하고 plot을 생성한다.
png("web_hits_over_week.png")
data <- read.table("part-00000")
plot(data, axes=FALSE, ann=FALSE, type="p", pch=".")
lines(c(1440*7,0), c(0, 0), col="gray")
for (i in 0:7) {
lines(c(1440,1440)*i, c(0, max(data)), col="gray")
}
dev.off()
각 실선 사이는 월~일요일을 나타낸다. 금,토요일이 방문자가 적은편이고 왜케 새벽에들 들어온데,,, 실선부근은 새벽시간대에 가까운건데,,, 뭔가 잘못됐나?? 주로 새벽시간대에 봇들이 돌아다닌다... 고로 이 웹서버에는 사람들이 방문하는 것보다는 봇이 더 많다... 뭐 이정도 ㅋㅋㅋ
지금까지 Hadoop을 이용해서 로그를 분석하는 과정을 보았는데,,, 대용량의 로그 데이터를 기반으로 어느 정도의 속도를 내는지 체크하는 일만 남았다. 이 데이터를 몇백GB로 부풀려서 얼마만큼 Hadoop이 속도를 내는지 몹시 궁금해진다.
IBM의 Many Eyes에 결과데이터를 시각화 해보았다. Many Eyes는 자신의 데이터를 올리고 이를 손쉽게? 시각화해주는 사이트로 어떠한 데이터를 어떠한 방식으로 시각화해야 할지에 대한 좋은 아이디어를 얻을 수 있다.
반응형
공지사항
최근에 올라온 글