
티스토리 뷰
반응형
13 난쟁이
Berkeley에서 발표한 The Landscape of Parallel Computing Research: A View from Berkeley를 보면 난쟁이(Dwarf)라는 개념을 이용해서 병렬 컴퓨팅 환경에서 어플리케이션들을 집합을 가지고 통신 및 전산 공통 패턴에 대해서 정리하고 있다.
핵심적인 것은 17p~19p에 걸쳐서 총 13개의 Dwarfs와 각각의 Dwarfs들이 Embedded Computing, General Purpose Computing, Machine Learning, Graphics/Games/Databases에서 어떠한 형태로 발현? 되는지를 요약하고 있다.
또한 2008년도 자신의 연구에 대한 문서를 보면 각 Dwarfs(Motif라는 표현)와 컴퓨팅분야, 자신들의 연구분야와의 연관성을 온도로 표현하고 있다.
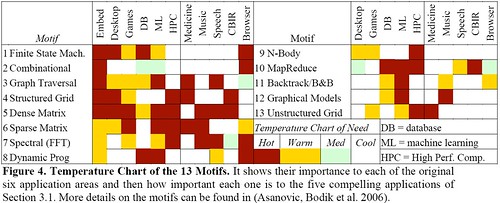
기존의 7 난쟁이에서 13 난쟁이로 확장되었는데, 기존의 몬테카를로(Monte Carlo) 부분이 MapReduce라는 이름으로 바뀐것이다. 7 난쟁이는 다음과 같다.
위의 문서에서는 위의 기존의 7 난쟁이에서 난쟁이들을 더 추가하면서 떠오르는 3개의 어플리케이션 도메인에 대해서 언급하고 있다. 3개의 어플리케이션 도메인은 다음과 같다.
Machine Learning은 요즘 인터넷의 방대한 정보와 함께 떠오르고 있는것이 확실한 도메인이고, 여기서 Dynamic programming, Backtrack and Branch-and-Bound를 추가하고 있으며, 많은 ML알고리즘이 이 영역에 포함되어 있다.( Support Vector Machine: Dense linear algebra, Principal Component Analysis: Dense or sparse linear algebra, Decision Trees: Graph traversal, Hashing: Combinational logic)
Database
Database Software 부분에서는 처음에 sort와 hasing에 대해서 언급하지만, 이보다 Large data와 Internet에서의 MapReduce와 Genetics(Blast-생물학데이터 서열 유사성 검색)부분을 언급하고 있다.
잠깐 Hadoop&MPI >> Hadoop 모임에서 질문이 바로 MPI와 Hadoop에 관한 것이었는데, 이를 MPI와 MapReudce로 좁혀서 생각한다면, MapReudce는 몬테카를로와 같이 병렬화하기 쉬운 따라서 곤란한 병렬화(Embarrassingly Parallel)라는 이름이 붙은 병렬화에 적합하다는 것이다.(한박사님이 말씀하셨듯이) 버클리 문서에서도 몬테카를로를 아예 MapReduce로 명칭을 바꿔 버렸다. MPI는 메세지패싱에 대한 규격?으로 메세지패싱을 통해서 분산된 메모리를 하나의 메모리처럼 사용할 수 있도록 해준다. 따라서 위에서 언급한 Dense Linear Algebar 등의 난쟁이들을 MPI로 구현할 수 있는 것이다. 물론 MapReduce도 MPI로 구현이 가능한 것이다.(이것도 한박사님이 말씀하셨구나 -.-)
Genetics와 MapReduce
Database 부분에서 언급한 Genetics(Blast) 는 이전 포스팅에서 언급한 것과 같이 Embarrassingly Parallel의 좋은 예이다. 데이터베이스 관점에서 대용량의 데이터는 HDFS에 분산해서 넣고 서열의 유사성 검색은 MapReduce로 쫘악 헤쳐서 해버리면 끝이 나버리는 간단한 병렬화! 이전부터 언능해야지 하면서도 늘 게으른 탓에 지금까지 손 놓고 있었는데, 저번 Hadoop모임에서 아파치 로그 분석을 Hadoop Streaming을 통해서 하시는걸 보고는 ^^
Hadoop과 Blast
Berkeley에서 발표한 The Landscape of Parallel Computing Research: A View from Berkeley를 보면 난쟁이(Dwarf)라는 개념을 이용해서 병렬 컴퓨팅 환경에서 어플리케이션들을 집합을 가지고 통신 및 전산 공통 패턴에 대해서 정리하고 있다.
핵심적인 것은 17p~19p에 걸쳐서 총 13개의 Dwarfs와 각각의 Dwarfs들이 Embedded Computing, General Purpose Computing, Machine Learning, Graphics/Games/Databases에서 어떠한 형태로 발현? 되는지를 요약하고 있다.
또한 2008년도 자신의 연구에 대한 문서를 보면 각 Dwarfs(Motif라는 표현)와 컴퓨팅분야, 자신들의 연구분야와의 연관성을 온도로 표현하고 있다.
13 모티프(난쟁이)
기존의 7 난쟁이에서 13 난쟁이로 확장되었는데, 기존의 몬테카를로(Monte Carlo) 부분이 MapReduce라는 이름으로 바뀐것이다. 7 난쟁이는 다음과 같다.
- Dense Linerar Alg ebra
- Sparse Linear Algebra
- Spectral Methods
- N-Body Methods
- Structured Grids
- Unstructured Grids
- Monte Carlo
위의 문서에서는 위의 기존의 7 난쟁이에서 난쟁이들을 더 추가하면서 떠오르는 3개의 어플리케이션 도메인에 대해서 언급하고 있다. 3개의 어플리케이션 도메인은 다음과 같다.
- Machine Learning
- Database Software
- Computer Graphics and Games
Machine Learning은 요즘 인터넷의 방대한 정보와 함께 떠오르고 있는것이 확실한 도메인이고, 여기서 Dynamic programming, Backtrack and Branch-and-Bound를 추가하고 있으며, 많은 ML알고리즘이 이 영역에 포함되어 있다.( Support Vector Machine: Dense linear algebra, Principal Component Analysis: Dense or sparse linear algebra, Decision Trees: Graph traversal, Hashing: Combinational logic)
Database
Database Software 부분에서는 처음에 sort와 hasing에 대해서 언급하지만, 이보다 Large data와 Internet에서의 MapReduce와 Genetics(Blast-생물학데이터 서열 유사성 검색)부분을 언급하고 있다.
잠깐 Hadoop&MPI >> Hadoop 모임에서 질문이 바로 MPI와 Hadoop에 관한 것이었는데, 이를 MPI와 MapReudce로 좁혀서 생각한다면, MapReudce는 몬테카를로와 같이 병렬화하기 쉬운 따라서 곤란한 병렬화(Embarrassingly Parallel)라는 이름이 붙은 병렬화에 적합하다는 것이다.(한박사님이 말씀하셨듯이) 버클리 문서에서도 몬테카를로를 아예 MapReduce로 명칭을 바꿔 버렸다. MPI는 메세지패싱에 대한 규격?으로 메세지패싱을 통해서 분산된 메모리를 하나의 메모리처럼 사용할 수 있도록 해준다. 따라서 위에서 언급한 Dense Linear Algebar 등의 난쟁이들을 MPI로 구현할 수 있는 것이다. 물론 MapReduce도 MPI로 구현이 가능한 것이다.(이것도 한박사님이 말씀하셨구나 -.-)
메세지 패싱
Genetics와 MapReduce
Database 부분에서 언급한 Genetics(Blast) 는 이전 포스팅에서 언급한 것과 같이 Embarrassingly Parallel의 좋은 예이다. 데이터베이스 관점에서 대용량의 데이터는 HDFS에 분산해서 넣고 서열의 유사성 검색은 MapReduce로 쫘악 헤쳐서 해버리면 끝이 나버리는 간단한 병렬화! 이전부터 언능해야지 하면서도 늘 게으른 탓에 지금까지 손 놓고 있었는데, 저번 Hadoop모임에서 아파치 로그 분석을 Hadoop Streaming을 통해서 하시는걸 보고는 ^^
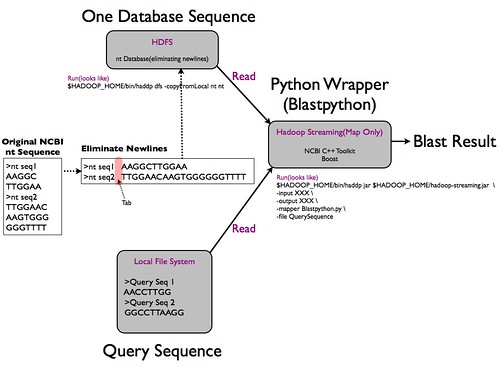
Hadoop과 Blast
맨 왼쪽의 NCBI nt Sequence의 용량은 25GB로 총 7,630,203개의 서열을 포함하고 있다. 하나의 서열정보는 2줄 이상으로 구성되어 있는데 이것을 하나의 라인으로(tab을 통해서 구분)만들고, HDFS에 넣고, Python으로 기존의 Blast 알고리즘을 구현한 프로그램에 대한 Wrapper를 만들어서 Hadoop상에서 돌리는 것으로,,, 이젠 Wrapper를 만들고 성능 테스트를 해봐야겠군,,,
Computing Graphics and Games
pass
마지막으로 위의 7 난쟁이에 이어 추가된 6개의 난쟁이는 다음과 같다.
pass
마지막으로 위의 7 난쟁이에 이어 추가된 6개의 난쟁이는 다음과 같다.
- combinational Logic
- Graph traversal
- Dynamic Programming
- Backtrack and Branch+Bound
- Construct Graphical Models
- Finite State Machine
반응형
공지사항
최근에 올라온 글