
 HiSeq vs. 454
HiSeq vs. 454
전세계적으로 HiSeq을 포함한 일루미나 장비가 가장 많은 사용되고 있다. 너가 그런거 어케 알어!?? 라고 물으신다면... 예전에도 언급했던 http://omicsmaps.com/ 여기서 확인 가능하다. 봐 아래 그림에서 보듯이 GA2랑 HiSeq 을 포함하면 다른 플랫폼보다 월등히 많지!! 그러니까 대세는 일루미나야 이 바보야!!! 라고 말한다면... 자 이건 미국내에서 일루미나 장비(GA2랑 HiSeq 모두 합한것)의 분포도이다. 특징은 지역적으로 드문드문 분포하며, 특정 지역에 엄청나게 그 수가 밀집되어 있다. 미국내 일루미나 장비의 분포 이에 반해 아래 그림은 454의 분포도이다. 비록 대수는 얼마 안되지만 골고루 퍼져 있는 것을 확인 할 수 있다. 이러한 분포의 특징은 단 미국내뿐만 아니라 전..
 우린 Apple App Store 아니 Genome App Store - Illumina BaseSpace
우린 Apple App Store 아니 Genome App Store - Illumina BaseSpace
Apple은 iPhone이나 MacOSX를 사용하는 사용자들이 손쉽게 클라우드 기반으로 Application을 찾아서 설치하고 업데이트 할 수 있는 Store를 운영하고 있다. 이러한 Store를 통해 일반 개발자들도 자신의 App을 등록하고 이를 통해 중간에 유통이니 광고니 이런 복잡다단한 중간 단계 없이 그저 Store에 등록하는 걸로 자신의 Appicaltion으로 수익을 낼 수 있게 되는 그런 그림이다. Apple App Store 화면 1. 일루미나 BaseSpace Illumina, Inc. (ILMN)ㅋ도 바로 이러한 모델을 내놓았는데 바로 BaseSpace AppStore이다. BaseSpace는 일루미나가 내놓은 Genomic Cloud Computing Environment로 너무 거창..
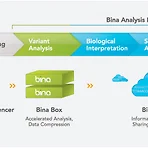 Bina Techlogies - 우린 genomics의 Apple이다
Bina Techlogies - 우린 genomics의 Apple이다
Apple은 Mac OSX, iMac, iCloud라는 운영체제와 이를 기반한 하드웨어와 클라우드를 갖추고 있다. 모두 자신들이 만들고 운영하고 있는 것이다. 바로 이러한 컨셉을 이쪽 업계에 반영한 회사가 있으니 바로 Bina Techlogies이다. 일반적으로 NGS 데이터를 사용하는 프로세스는 아래와 같이 요약 될 수 있는데, sequencer에서 생산된 데이터는 Bina Box라는 하드웨어를 통해 1/2차 분석과 데이터 압축등의 과정을 수행한다. Bina Box는 CPU, GPU, FPGA로 구성되었으며 (iMac), 하드웨어에 최적화된 Linux Kernel을 사용하고있다. (Mac OSX) 사용자들은 이들을 이용하여 특정 도메인(간단히 분석작업)에 최적화된 알고리즘이나 파이프라인을 구성할 수 있..
 BGI의 공짜 분석 서비스 EasyGenomics
BGI의 공짜 분석 서비스 EasyGenomics
금번 Bio-IT World Conference & Expo에서 BGI의 NGS 분석 서비스가 화두거리중의 하나였다. 물론 BGI가 서비스하는 것이 획기적이거나 한것보다는 바로 분석 비용에 있어서의 free를 선언했기 때문이다. 그럼 이번에 새롭게 발표한 중국 BGI의 EasyGenomics 서비스에 대해서 살펴보도록 하겠다. BGI는 데이터 분석에서의 나타나는 문제점들의 다음의 4가지 관점에서 지적하고 있는데, 분석의 각 단계에 따라 문제점들을 말하고 있다. Primary Analyis NGS 장비에서 이미지를 읽어 Base Calling하는 단계이며, 이 단계에서는 Data throughput과 Data storage를 지적하고 있다. 일반적으로 NGS장비에서 생산된 데이터를 지역적으로 멀리 떨어진 ..
 상용 및 오픈소스를 이용한 NGS 분석 서비스의 Mapping Rate 비교
상용 및 오픈소스를 이용한 NGS 분석 서비스의 Mapping Rate 비교
아래 글에서 언급했던 논문의 서플을 보면 다음과 같이 NGS 분석 서비스를 비교한 테이블이 나온다. 테이블의 첫번째 나오는 것이 논문 저자들이 만든 HugeSeq이라는 파이프라인에 대한 것으로 다음과 같은 항목에 대해서 각각의 서비스들을 비교했다. 크게 항목을 나누자면 웹기반의 서비스와 직접 다운로드해서 설치하는 것으로 나눌 수 있다. 우선 웹 기반의 서비스중 대표격인 DNAnexus는 Align, SNP Call, Indel Call을 지원하지만 아직 SV (Structural Variant) Call은 지원하지 않고 있으며 commercial한 서비스이다. 즉 커머셜하면서 웹 기반으로 제공되는 서비스 중 최고를 달리고 있다. 테이블 1. NGS 데이터 분석 서비스 비교 Alignment SNP Cal..
 동일 individual의 서로 다른 sample, platform, analysis tool을 사용한 분석
동일 individual의 서로 다른 sample, platform, analysis tool을 사용한 분석
NGS를 수행하는데에 있어서 동일한 사람에 대해서 혈액 vs. 타액, Illumina HiSeq 2000 vs. Complete Genomics, GATK vs. SAMtools 자 이제 각각의 대결?을 한번 훑어 보기로 하자. 물론 정답은 없다. 걍 한번 심심하니까 한번 보는거다. Performance comparison of whole-genome sequencing platforms.Lam HY, Clark MJ, Chen R, Chen R, Natsoulis G, O'Huallachain M, Dewey FE, Habegger L, Ashley EA, Gerstein MB, Butte AJ, Ji HP, Snyder M.Nat Biotechnol. 2011 Dec 18;30(1):78-82. do..