반응형
GWAS, 전장유전체 연관 분석
기본적으로 GWAS(genome wide association study)에서는 common disease-common variant(CDCV) 가설을 기반으로 연구가 진행된다. 즉, 일반적으로 인류 집단에 광범위하게 퍼져있는 질병(common disease)의 원인은, 마찬가지로 인류 집단의 유전정보 전체에서 광범위하게 발견되는 변이(common variants)가 원인이라는 가설을 기반으로하고 있다.
그 과정은 간단히 설명하자면, 질병에 걸린 사람과 그렇지 않은 사람을 나누어 질병에 걸린 사람들에게서 통계적으로 유의하게 나타난 유전변이를 찾아 이는 질병에 관련한 유전변이이며 이 변이를 가지고 있다면 그렇지 않은 사람에 비해 해당 질병에 대해 ~배 위험도를 지닌다고 말하게 된다.
GWAS의 위기
하지만, common한 질병이라는 것이 단순히 유전변이라는 원인 하나만으로 발생하는 것은 아니며, 지난 5년간 미국의 NIH와 영국의 Wellcome trust 등에서 막대한 연구비를 투자한 GWAS 연구를 수행하여 엄청난 결과를 얻었지만, 그에 반해 실제 질병에 대한 치료나 예방에 획기적인 방법은 아직 없는 현실이기에 조심스럽게 GWAS에 대한 회의의 목소리가 나오고 있다.
이코노미스트에서는 "위기에 직면한 인간 유전체(The looming crisis in human genetic)"라고 표현하기 하기에 이르렀다. 이 뿐만 아니라, Xconomy에서는 "곧 사라질 5가지 바이오기술(Five Biotechnologies That Will Fade Away This Decade)"의 첫번째로 바로 SNP기반의 GWAS를 꼽기도 했다1.
질병과 유전변이의 관계
그렇다면, 실제 GWAS 연구를 통해 밝혀진 유전변이가 정말 실제 임상에서는 쓸모 없는 쓰레기인가? 라는 질문에 어떻게 대답해야 하는 것일까? 그냥 막연하게 질병이라는것이 "유전적+환경적+알파... 니까 그냥 유전적인것도 무시못하는거야"라고 무턱대고 말하는 것을 들어야 하는건지에 대한 해답에 대해서 살펴보려고 한다.
다수의 NEJM2 발표 논문들3에서 비록 각각의 유전변이(SNP)가 필연적으로 질병의 발병(susceptibility)에 미치는 영향은 비록 적지만 질병의 진단이나 예측에서 이러한 다수의 유전변이 결합이 유용할 수 있다고 제안하고 있다.자 어떻게 유용한지 한번 보자.
문헌을 통한 질병관련 유전변이의 선택
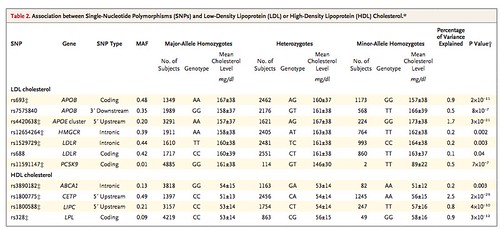
우선 질병과 관련된 유전변이를 문헌을 통해 검색한다. 아래 표는 심혈관(cardiovascular) 질환과 관련이 있는 LDL, HDL 콜레스테롤4과 그에 관련된 유전변이로 논문에서는 같은 유전자에 속하는 유전변이는 하나만 선택해서 총 9개의 유전변이를 사용한다.
유전변이들의 점수 매기기, Genotype Score
총 9개의 유전변이는 allele가 2개씩이기 때문에 총 18(9x2)개의 allele로 나뉘어 Risk allele를 몇개 가지고 있느냐에 따라서 그 갯수를 Genotype Score로 명명하고 있다
예를 들어, 당뇨와 관련된 유전변이 A, B 두개가 존재하고 각각의 Risk allele가 A, G인 경우 총 2명에 대해서 다음과 같이 Genotype Score를 생성하게 된다. 1번 사람은 당뇨와 관련해서 Genotype Score가 3점, 2번 사람은 1점이 된다. 그렇다면 1번 사람이 당뇨에 대해서 위험한 유전변이를 더 많이 가지고 있다는 말이 된다. 그럼 실제 Genotype Score가 높은 사람은 질병에 더 위험한지를 실제 데이터를 가지고 살펴보자.
Genotype Score와 질병의 관계
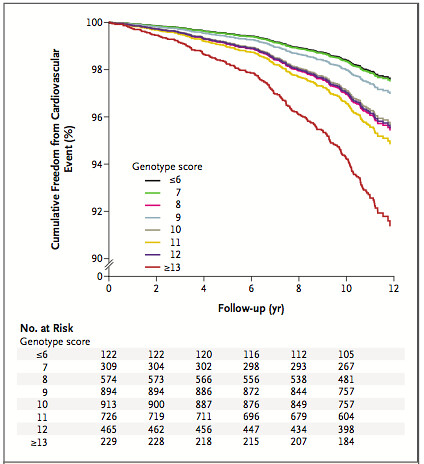
Genotype Score와의 실제 심혈관 질환과의 관계를 알아보기 위해 "Malmö Diet and Cancer Study" 코호트의 5,414명을 10여년간 추적 조사를 한 결과 238명이 심혈관 질환에 노출되게 되었고 이 사람들이 Genotype Score와 어떤 상관관계를 가지는지를 보여준다.
모든 사람은 심혈관 질환에 대해서 100 즉 심혈관 질환과 노출되지 않지만, X축의 시간(년단위)이 지나가면서 Genotype Score가 6이하인 사람들(검은색선)은 10년이 지난 후 약 98%인 반면 Score가 13이상으로 높은 사람들(빨간색선)은 92%를 보이고 있다.
전체적으로 Genotype Score가 높은 사람들 즉, 심혈관과 관련된 유전변이의 갯수가 많으면 많은 사람들일수록 시간이 지남에 따라 실제 심혈관 질환에 Score가 낮은 사람에 비해 더 쉽게 질환에 노출되는 경향을 보이고 있음을 알 수 있다.
유전변이들외의 영향과 질병과의 관계
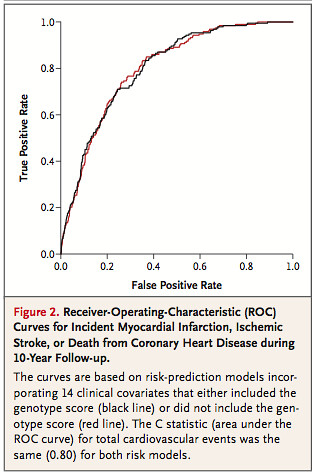
마지막으로 심혈관 질환과 관련된 유전변이와 다른 14가지의 인자들과 유전변이를 포함한 c-statistics5를 보여준다. 검은선은 유전정보(Genotype Score)를 넣은 것이며, 빨간선은 유전정보를 넣지 않은것으로 유전정보를 넣거나 빼도 실제 임상적으로는 0.86로 별반 차이가 없다.
비록 각각의 유전변이가 필연적으로 질병의 발병(susceptibility)에 적은 영향을 미치지만은 이는 질병의 진단이나 예측에 다수의 변이 결합이 유용할수 있다고 제안하고 있다고 볼 수 있다.
향후 질병의 발생이나 예측 모델에 유전변이 또한 중요한 변수가 될 수 있으며, 지금 현재로는 그 영향이 미미하지만, 충분히 활용될 수 있음을 시사한다고 할 수 있겠다. 현재 23andME나 기타 DTC 유전자 검사 서비스 문헌에서 언급한 유전변이 하나가 아닌 여러개를 가지고 위험도를 표현하고 있는데, 이는 분명 유전변이 하나에 비해 질병을 좀 더 잘 설명할 수 있다는 것을 의미한다고 할 수 있다7.
좋은 측면에서 보면 위와 같이 유용할 수 있다고 끝을 낼 수도 있겠지만은, 좀 비관적인 측면에서 본다면 아무리 유전적으로 해당 질병에 취약 하다고 한들 담배 하나 끊는다면 해당 질병에 대한 위험도를 획기적으로 낮출 수 있다고 할 수도 있게된다는 것이다. 담배 끊어요. 유전적인것은 웃어 넘기고~~~ ^^;;
기본적으로 GWAS(genome wide association study)에서는 common disease-common variant(CDCV) 가설을 기반으로 연구가 진행된다. 즉, 일반적으로 인류 집단에 광범위하게 퍼져있는 질병(common disease)의 원인은, 마찬가지로 인류 집단의 유전정보 전체에서 광범위하게 발견되는 변이(common variants)가 원인이라는 가설을 기반으로하고 있다.
그 과정은 간단히 설명하자면, 질병에 걸린 사람과 그렇지 않은 사람을 나누어 질병에 걸린 사람들에게서 통계적으로 유의하게 나타난 유전변이를 찾아 이는 질병에 관련한 유전변이이며 이 변이를 가지고 있다면 그렇지 않은 사람에 비해 해당 질병에 대해 ~배 위험도를 지닌다고 말하게 된다.
GWAS의 위기
하지만, common한 질병이라는 것이 단순히 유전변이라는 원인 하나만으로 발생하는 것은 아니며, 지난 5년간 미국의 NIH와 영국의 Wellcome trust 등에서 막대한 연구비를 투자한 GWAS 연구를 수행하여 엄청난 결과를 얻었지만, 그에 반해 실제 질병에 대한 치료나 예방에 획기적인 방법은 아직 없는 현실이기에 조심스럽게 GWAS에 대한 회의의 목소리가 나오고 있다.
이코노미스트에서는 "위기에 직면한 인간 유전체(The looming crisis in human genetic)"라고 표현하기 하기에 이르렀다. 이 뿐만 아니라, Xconomy에서는 "곧 사라질 5가지 바이오기술(Five Biotechnologies That Will Fade Away This Decade)"의 첫번째로 바로 SNP기반의 GWAS를 꼽기도 했다1.
질병과 유전변이의 관계
그렇다면, 실제 GWAS 연구를 통해 밝혀진 유전변이가 정말 실제 임상에서는 쓸모 없는 쓰레기인가? 라는 질문에 어떻게 대답해야 하는 것일까? 그냥 막연하게 질병이라는것이 "유전적+환경적+알파... 니까 그냥 유전적인것도 무시못하는거야"라고 무턱대고 말하는 것을 들어야 하는건지에 대한 해답에 대해서 살펴보려고 한다.
다수의 NEJM2 발표 논문들3에서 비록 각각의 유전변이(SNP)가 필연적으로 질병의 발병(susceptibility)에 미치는 영향은 비록 적지만 질병의 진단이나 예측에서 이러한 다수의 유전변이 결합이 유용할 수 있다고 제안하고 있다.자 어떻게 유용한지 한번 보자.
문헌을 통한 질병관련 유전변이의 선택
우선 질병과 관련된 유전변이를 문헌을 통해 검색한다. 아래 표는 심혈관(cardiovascular) 질환과 관련이 있는 LDL, HDL 콜레스테롤4과 그에 관련된 유전변이로 논문에서는 같은 유전자에 속하는 유전변이는 하나만 선택해서 총 9개의 유전변이를 사용한다.
유전변이들의 점수 매기기, Genotype Score
총 9개의 유전변이는 allele가 2개씩이기 때문에 총 18(9x2)개의 allele로 나뉘어 Risk allele를 몇개 가지고 있느냐에 따라서 그 갯수를 Genotype Score로 명명하고 있다
예를 들어, 당뇨와 관련된 유전변이 A, B 두개가 존재하고 각각의 Risk allele가 A, G인 경우 총 2명에 대해서 다음과 같이 Genotype Score를 생성하게 된다. 1번 사람은 당뇨와 관련해서 Genotype Score가 3점, 2번 사람은 1점이 된다. 그렇다면 1번 사람이 당뇨에 대해서 위험한 유전변이를 더 많이 가지고 있다는 말이 된다. 그럼 실제 Genotype Score가 높은 사람은 질병에 더 위험한지를 실제 데이터를 가지고 살펴보자.
| 유전변이 A (risk A) |
유전변이 B (risk G) |
Genotype Score |
|
| 사람 1 |
AA | AG | 3 |
| 사람 2 |
AG | AA |
1 |
Genotype Score와의 실제 심혈관 질환과의 관계를 알아보기 위해 "Malmö Diet and Cancer Study" 코호트의 5,414명을 10여년간 추적 조사를 한 결과 238명이 심혈관 질환에 노출되게 되었고 이 사람들이 Genotype Score와 어떤 상관관계를 가지는지를 보여준다.
모든 사람은 심혈관 질환에 대해서 100 즉 심혈관 질환과 노출되지 않지만, X축의 시간(년단위)이 지나가면서 Genotype Score가 6이하인 사람들(검은색선)은 10년이 지난 후 약 98%인 반면 Score가 13이상으로 높은 사람들(빨간색선)은 92%를 보이고 있다.
전체적으로 Genotype Score가 높은 사람들 즉, 심혈관과 관련된 유전변이의 갯수가 많으면 많은 사람들일수록 시간이 지남에 따라 실제 심혈관 질환에 Score가 낮은 사람에 비해 더 쉽게 질환에 노출되는 경향을 보이고 있음을 알 수 있다.
유전변이들외의 영향과 질병과의 관계
마지막으로 심혈관 질환과 관련된 유전변이와 다른 14가지의 인자들과 유전변이를 포함한 c-statistics5를 보여준다. 검은선은 유전정보(Genotype Score)를 넣은 것이며, 빨간선은 유전정보를 넣지 않은것으로 유전정보를 넣거나 빼도 실제 임상적으로는 0.86로 별반 차이가 없다.
비록 각각의 유전변이가 필연적으로 질병의 발병(susceptibility)에 적은 영향을 미치지만은 이는 질병의 진단이나 예측에 다수의 변이 결합이 유용할수 있다고 제안하고 있다고 볼 수 있다.
향후 질병의 발생이나 예측 모델에 유전변이 또한 중요한 변수가 될 수 있으며, 지금 현재로는 그 영향이 미미하지만, 충분히 활용될 수 있음을 시사한다고 할 수 있겠다. 현재 23andME나 기타 DTC 유전자 검사 서비스 문헌에서 언급한 유전변이 하나가 아닌 여러개를 가지고 위험도를 표현하고 있는데, 이는 분명 유전변이 하나에 비해 질병을 좀 더 잘 설명할 수 있다는 것을 의미한다고 할 수 있다7.
좋은 측면에서 보면 위와 같이 유용할 수 있다고 끝을 낼 수도 있겠지만은, 좀 비관적인 측면에서 본다면 아무리 유전적으로 해당 질병에 취약 하다고 한들 담배 하나 끊는다면 해당 질병에 대한 위험도를 획기적으로 낮출 수 있다고 할 수도 있게된다는 것이다. 담배 끊어요. 유전적인것은 웃어 넘기고~~~ ^^;;
- 위의 기사들에서는 GWAS가 실효성을 거두지 못하는 이유가 기본적으로 인구집단에서 광범위하게 발견되는 유전변이(기존의 Illumina, Affymetrix의 SNP Chip기반)를 가지고는 찾을 수 없는 드문 변이(rare variants)가 질병의 원인일 수도 있기 때문에 그 대안으로 Next generation sequencing가 이러한 한계를 극복하는데 일조할 수 있다는 글이다. [본문으로]
- The New England Journal of Medicine (NEJM.org) 한글 NEJM 초록은 http://www.questis.co.kr/ 영국에서 만들어진 저널 아님, 미국 동북부의 코네티컷, 메세추세츠를 포함한 지역을 뉴 잉글랜드라고 부름. ^^;; [본문으로]
- 전립선암과 심혈관 질환Cumulative association of five genetic variants with prostate cancePolymorphisms associated with cholesterol and risk of cardiovascular events그리고, 유방암의 스크리닝에 일반적인 유전적 마커를 사용하는Polygenes, Risk Prediction, and Targeted Prevention of Breast Cancer좀 더 최근에는 18개의 SNP를 이용한 제2당뇨병의 예측에 대한Genotype Score in Addition to Common Risk Factors for Prediction of Type 2 Diabetes [본문으로]
- 콜레스테롤은 비중에 따라 HDL콜레스테롤(고밀도)과 LDL콜레스테롤(저밀도)로 나뉘며 우리 몸에서 동맥경화와 관련하여 중요한 역할을 한다.HDL 콜레스테롤은 혈관 안에 붙어있는 LDL 콜레스테롤을 끌어들여 간으로 회수하는 혈관 청소부로서, 동맥경화를 억제하며, LDL 콜레스테롤은 동맥경화를 유발하는 몸에 해로운 콜레스테롤이다. [본문으로]
- 새로운 척도A(continuous variable)가 병이 있는지 없는지(binary variable)을 얼마나 잘 구별해 내는지를 보기 위해서는 ROC curve의 면적을 측정 함으로써 그 면적이 클수록 잘 구별해 내고 식별(discrimination)을 잘 한다고 이야기한다.진단 방법의 효율성을 판단하는 방법 중 널리 사용되는 것으로 민감도(sensitivity)와 특이도(specificity)가 어떤 관계를 가지는지를 보여준다.민감도: 진짜 환자 중 검사 벙법이 환자를 얼마나 잘 골라 내는가?를 의미특이도: 진짜 정상 중 검사 방법이 정상을 얼마나 잘 골라 내는가?를 의미 [본문으로]
- 임상에서 사용가능한 수치 [본문으로]
- 하지만, 이러한 문헌에서 언급한 유전변이가 모두 해당 질병에 대해서 옳은 판단을 줄 수 있을지 또한 분명 짚고 넘어가야 할 부분이라고 생각된다. 본 NEJM 논문에서 사용한 9개의 유전변이는 좋은 결과를 보였지만, 질이 좋지 않은?? 논문에서 언급되어진 유전변이들이 다수 포함되었다면 아마 다른 양상을 보일수도 있다는 것이다. [본문으로]
반응형